TimeMixin
- class deepinv.physics.TimeMixin[source]
Bases:
objectBase class for temporal capabilities for physics and models.
Implements various methods to add or remove the time dimension.
Also provides template methods for temporal physics to implement.
- static average(x: Tensor, mask: Tensor | None = None, dim: int = 2) Tensor[source]
Flatten time dim of x by averaging across frames. If mask is non-overlapping in time dim, then this will simply be the sum across frames.
- Parameters:
x (Tensor) – input tensor of shape (B,C,T,H,W) (e.g. time-varying k-space)
mask (Tensor) – mask showing where
xis non-zero. If not provided, then calculated fromx.dim (int) – time dimension, defaults to 2 (i.e. shape B,C,T,H,W)
- Return Tensor:
flattened tensor with time dim removed of shape (B,C,H,W)
- static flatten(x: Tensor) Tensor[source]
Flatten time dim into batch dim.
Lets non-dynamic algorithms process dynamic data by treating time frames as batches.
- Parameters:
x (Tensor) – input tensor of shape (B, C, T, H, W)
- Return Tensor:
output tensor of shape (B*T, C, H, W)
- static flatten_C(x: Tensor) Tensor[source]
Flatten time dim into channel dim.
Use when channel dim doesn’t matter and you don’t want to deal with annoying batch dimension problems (e.g. for transforms).
- Parameters:
x (Tensor) – input tensor of shape (B, C, T, H, W)
- Return Tensor:
output tensor of shape (B, C*T, H, W)
- static repeat(x: Tensor, target: Tensor, dim: int = 2) Tensor[source]
Repeat static image across new time dim T times. Opposite of
average.- Parameters:
x (Tensor) – input tensor of shape (B,C,H,W)
target (Tensor) – any tensor of desired shape (B,C,T,H,W)
dim (int) – time dimension, defaults to 2 (i.e. shape B,C,T,H,W)
- Return Tensor:
tensor with new time dim of shape B,C,T,H,W
Examples using TimeMixin:
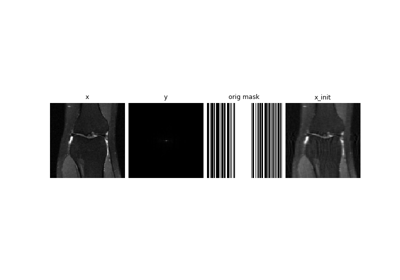
Self-supervised MRI reconstruction with Artifact2Artifact
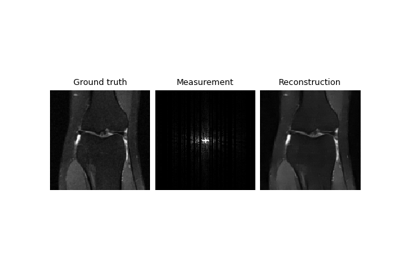
Self-supervised learning with Equivariant Imaging for MRI.