
Note
New to DeepInverse? Get started with the basics with the 5 minute quickstart tutorial..
Self-supervised learning with Equivariant Imaging for MRI.#
This example shows you how to train a reconstruction network for an MRI inverse problem on a fully self-supervised way, i.e., using measurement data only.
The equivariant imaging loss is presented in Chen et al.[1].
from pathlib import Path
import torch
from torch.utils.data import DataLoader
from torchvision import transforms
import deepinv as dinv
from deepinv.datasets import SimpleFastMRISliceDataset
from deepinv.utils import load_degradation
from deepinv.models.utils import get_weights_url
from deepinv.models import MoDL
Setup paths for data loading and results.#
Selected GPU 0 with 3911.25 MiB free memory
Load base image datasets and degradation operators.#
In this example, we use a mini demo subset of the single-coil FastMRI dataset as the base image dataset, consisting of 2 knee images of size 320x320.
See also
- Datasets
deepinv.datasets.FastMRISliceDatasetdeepinv.datasets.SimpleFastMRISliceDataset We provide convenient datasets to easily load both raw and reconstructed FastMRI images. You can download more data on the FastMRI site.
Important
By using this dataset, you confirm that you have agreed to and signed the FastMRI data use agreement.
Note
We reduce to the size to 128x128 for faster training in the demo.
operation = "MRI"
img_size = 128
transform = transforms.Compose([transforms.Resize(img_size)])
train_dataset = SimpleFastMRISliceDataset(
transform=transform, train_percent=0.5, train=True, download=True
)
test_dataset = SimpleFastMRISliceDataset(
transform=transform, train_percent=0.5, train=False
)
Generate a dataset of knee images and load it.#
mask = load_degradation("mri_mask_128x128.npy")
# defined physics
physics = dinv.physics.MRI(mask=mask, device=device)
# Use parallel dataloader if using a GPU to speed up training,
# otherwise, as all computes are on CPU, use synchronous data loading.
num_workers = 4 if torch.cuda.is_available() else 0
n_images_max = (
900 if torch.cuda.is_available() else 5
) # number of images used for training
my_dataset_name = "demo_equivariant_imaging"
measurement_dir = DATA_DIR / "fastmri" / operation
deepinv_datasets_path = dinv.datasets.generate_dataset(
train_dataset=train_dataset,
test_dataset=test_dataset,
physics=physics,
device=device,
save_dir=measurement_dir,
train_datapoints=n_images_max,
num_workers=num_workers,
dataset_filename=str(my_dataset_name),
)
train_dataset = dinv.datasets.HDF5Dataset(path=deepinv_datasets_path, train=True)
test_dataset = dinv.datasets.HDF5Dataset(path=deepinv_datasets_path, train=False)
Dataset has been saved at measurements/fastmri/MRI/demo_equivariant_imaging0.h5
Set up the reconstruction network#
As a (static) reconstruction network, we use an unrolled network
(half-quadratic splitting) with a trainable denoising prior based on the
DnCNN architecture which was proposed in MoDL Aggarwal et al.[2].
See deepinv.models.MoDL for details.
Set up the training parameters#
We choose a self-supervised training scheme with two losses: the measurement consistency loss (MC) and the equivariant imaging loss (EI). The EI loss requires a group of transformations to be defined. The forward model should not be equivariant to these transformations Tachella et al.[3]. Here we use the group of 4 rotations of 90 degrees, as the accelerated MRI acquisition is not equivariant to rotations (while it is equivariant to translations).
See docs for full list of available transforms.
Note
We use a pretrained model to reduce training time. You can get the same results by training from scratch for 150 epochs using a larger knee dataset of ~1000 images.
epochs = 1 # choose training epochs
learning_rate = 5e-4
batch_size = 16 if torch.cuda.is_available() else 1
# choose self-supervised training losses
# generates 4 random rotations per image in the batch
losses = [dinv.loss.MCLoss(), dinv.loss.EILoss(dinv.transform.Rotate(n_trans=4))]
# choose optimizer and scheduler
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate, weight_decay=1e-8)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=int(epochs * 0.8) + 1)
# start with a pretrained model to reduce training time
file_name = "new_demo_ei_ckp_150_v3.pth"
url = get_weights_url(model_name="demo", file_name=file_name)
ckpt = torch.hub.load_state_dict_from_url(
url,
map_location=lambda storage, loc: storage,
file_name=file_name,
)
# load a checkpoint to reduce training time
model.load_state_dict(ckpt["state_dict"])
optimizer.load_state_dict(ckpt["optimizer"])
/local/jtachell/deepinv/deepinv/deepinv/transform/rotate.py:49: UserWarning: The default interpolation mode will be changed to bilinear interpolation in the near future. Please specify the interpolation mode explicitly if you plan to keep using nearest interpolation.
warn(
Train the network#
To simulate a realistic self-supervised learning scenario, we do not use any supervised metrics for training, such as PSNR or SSIM, which require clean ground truth images.
Tip
We can use the same self-supervised loss for evaluation, as it does not require clean images,
to monitor the training process (e.g. for early stopping). This is done automatically when metrics=None and early_stop>0 in the trainer.
verbose = True # print training information
train_dataloader = DataLoader(
train_dataset, batch_size=batch_size, num_workers=num_workers, shuffle=True
)
test_dataloader = DataLoader(
test_dataset, batch_size=batch_size, num_workers=num_workers, shuffle=False
)
# Initialize the trainer
trainer = dinv.Trainer(
model,
physics=physics,
epochs=epochs,
scheduler=scheduler,
losses=losses,
optimizer=optimizer,
train_dataloader=train_dataloader,
eval_dataloader=test_dataloader,
compute_eval_losses=True, # use self-supervised loss for evaluation
early_stop_on_losses=True, # stop using self-supervised eval loss
metrics=None, # no supervised metrics
early_stop=2, # early stop using the self-supervised loss on the test set
plot_images=True,
device=device,
save_path=str(CKPT_DIR / operation),
verbose=verbose,
show_progress_bar=False, # disable progress bar for better vis in sphinx gallery.
ckp_interval=10,
)
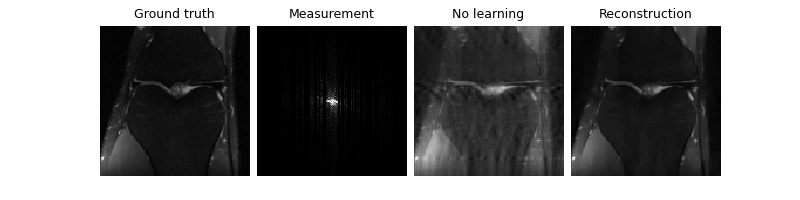
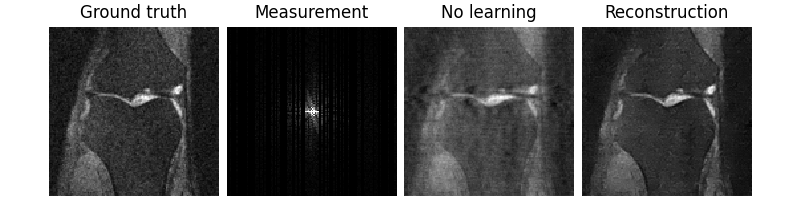
model = trainer.train()

/local/jtachell/deepinv/deepinv/deepinv/training/trainer.py:1337: UserWarning: non_blocking_transfers=True but DataLoader.pin_memory=False; set pin_memory=True to overlap host-device copies with compute.
self.setup_train()
The model has 187019 trainable parameters
Train epoch 0: MCLoss=0.0, EILoss=0.0, TotalLoss=0.0
Eval epoch 0: MCLoss=0.0, EILoss=0.0, TotalLoss=0.0
Best model saved at epoch 1
Test the network#
We now assume that we have access to a small test set of ground-truth images to evaluate the performance of the trained network. and we compute the PSNR between the denoised images and the clean ground truth images.
trainer.test(test_dataloader, metrics=dinv.metric.PSNR())
/local/jtachell/deepinv/deepinv/deepinv/training/trainer.py:1529: UserWarning: non_blocking_transfers=True but DataLoader.pin_memory=False; set pin_memory=True to overlap host-device copies with compute.
self.setup_train(train=False)
Eval epoch 0: MCLoss=0.0, EILoss=0.0, TotalLoss=0.0, PSNR=37.517, PSNR no learning=32.749
Test results:
PSNR no learning: 32.749 +- 0.000
PSNR: 37.517 +- 0.000
{'PSNR no learning': 32.74856948852539, 'PSNR no learning_std': 0.0, 'PSNR': 37.51734161376953, 'PSNR_std': 0.0}
- References:
Total running time of the script: (14 minutes 10.528 seconds)