
Note
New to DeepInverse? Get started with the basics with the 5 minute quickstart tutorial..
Self-supervised denoising with the Neighbor2Neighbor loss.#
This example shows you how to train a denoiser network in a fully self-supervised way, i.e., using noisy images only via the Neighbor2Neighbor loss, which exploits the local correlation of natural images.
The Neighbor2Neighbor loss is presented in Huang et al.[1] and is defined as:
where \(A_1\) and \(A_2\) are two masks, each choosing a different neighboring map, \(R\) is the trainable denoiser network, \(\gamma>0\) is a regularization parameter and no gradient is propagated when computing \(R(y)\).
from pathlib import Path
import torch
from torch.utils.data import DataLoader
from torchvision import transforms, datasets
import deepinv as dinv
from deepinv.models.utils import get_weights_url
from deepinv.utils import get_cache_home
Setup paths for data loading and results.#
BASE_DIR = Path(".")
DATA_DIR = BASE_DIR / "measurements"
CKPT_DIR = BASE_DIR / "ckpts"
ORIGINAL_DATA_DIR = get_cache_home() / "datasets" / "MNIST"
# Set the global random seed from pytorch to ensure reproducibility of the example.
torch.manual_seed(0)
device = dinv.utils.get_device()
Selected GPU 0 with 3910.25 MiB free memory
Load base image datasets#
In this example, we use the MNIST dataset as the base image dataset.
operation = "denoising_n2n"
train_dataset_name = "MNIST"
transform = transforms.Compose([transforms.ToTensor()])
train_dataset = datasets.MNIST(
root=ORIGINAL_DATA_DIR, train=True, transform=transform, download=True
)
test_dataset = datasets.MNIST(
root=ORIGINAL_DATA_DIR, train=False, transform=transform, download=True
)
Generate a dataset of noisy images#
We generate a dataset of noisy images corrupted by Poisson noise.
Note
We use a subset of the whole training set to reduce the computational load of the example.
We recommend to use the whole set by setting n_images_max=None to get the best results.
# defined physics
physics = dinv.physics.Denoising(dinv.physics.PoissonNoise(0.1))
# Use parallel dataloader if using a GPU to speed up training,
# otherwise, as all computes are on CPU, use synchronous data loading.
num_workers = 4 if torch.cuda.is_available() else 0
n_images_max = (
100 if torch.cuda.is_available() else 5
) # number of images used for training
my_dataset_name = "demo_n2n"
measurement_dir = DATA_DIR / train_dataset_name / operation
deepinv_datasets_path = dinv.datasets.generate_dataset(
train_dataset=train_dataset,
test_dataset=test_dataset,
physics=physics,
device=device,
save_dir=measurement_dir,
train_datapoints=n_images_max,
test_datapoints=n_images_max,
num_workers=num_workers,
dataset_filename=str(my_dataset_name),
)
train_dataset = dinv.datasets.HDF5Dataset(path=deepinv_datasets_path, train=True)
test_dataset = dinv.datasets.HDF5Dataset(path=deepinv_datasets_path, train=False)
Dataset has been saved at measurements/MNIST/denoising_n2n/demo_n2n0.h5
Set up the denoiser network#
We use a simple U-Net architecture with 2 scales as the denoiser network.
model = dinv.models.ArtifactRemoval(
dinv.models.UNet(in_channels=1, out_channels=1, scales=2).to(device)
)
Set up the training parameters#
We set deepinv.loss.Neighbor2Neighbor as the training loss.
Note
We use a pretrained model to reduce training time. You can get the same results by training from scratch for 50 epochs.
epochs = 1 # choose training epochs
learning_rate = 5e-4
batch_size = 32 if torch.cuda.is_available() else 1
# choose self-supervised training loss
loss = dinv.loss.Neighbor2Neighbor()
# choose optimizer and scheduler
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate, weight_decay=1e-8)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=int(epochs * 0.8) + 1)
# start with a pretrained model to reduce training time
file_name = "ckp_50_demo_n2n.pth"
url = get_weights_url(model_name="demo", file_name=file_name)
ckpt = torch.hub.load_state_dict_from_url(
url, map_location=lambda storage, loc: storage, file_name=file_name
)
# load a checkpoint to reduce training time
model.load_state_dict(ckpt["state_dict"])
optimizer.load_state_dict(ckpt["optimizer"])
Train the network#
To simulate a realistic self-supervised learning scenario, we do not use any supervised metrics for training, such as PSNR or SSIM, which require clean ground truth images.
Tip
We can use the same self-supervised loss for evaluation, as it does not require clean images,
to monitor the training process (e.g. for early stopping). This is done automatically when metrics=None and early_stop>0 in the trainer.
verbose = True # print training information
train_dataloader = DataLoader(
train_dataset, batch_size=batch_size, num_workers=num_workers, shuffle=True
)
test_dataloader = DataLoader(
test_dataset, batch_size=batch_size, num_workers=num_workers, shuffle=False
)
# Initialize the trainer
trainer = dinv.Trainer(
model=model,
physics=physics,
epochs=epochs,
scheduler=scheduler,
losses=loss,
optimizer=optimizer,
device=device,
train_dataloader=train_dataloader,
eval_dataloader=test_dataloader,
metrics=None, # no supervised metrics
compute_eval_losses=True, # use self-supervised loss for evaluation
early_stop_on_losses=True, # stop using self-supervised eval loss
early_stop=2, # early stop using the self-supervised loss on the test set
plot_images=True,
save_path=str(CKPT_DIR / operation),
verbose=verbose,
show_progress_bar=False, # disable progress bar for better vis in sphinx gallery.
)
model = trainer.train()
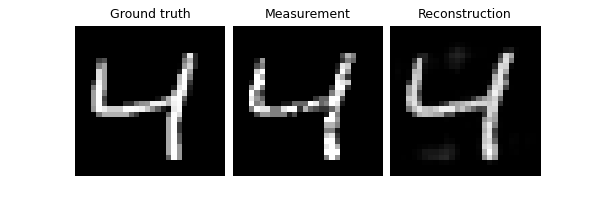
/local/jtachell/deepinv/deepinv/deepinv/training/trainer.py:1356: UserWarning: non_blocking_transfers=True but DataLoader.pin_memory=False; set pin_memory=True to overlap host-device copies with compute.
self.setup_train()
The model has 444737 trainable parameters
Train epoch 0: TotalLoss=0.068
Eval epoch 0: TotalLoss=0.065
Best model saved at epoch 1
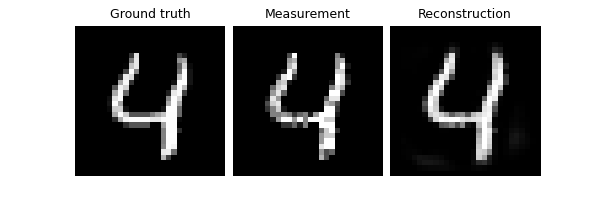
Test the network#
We now assume that we have access to a small test set of clean images to evaluate the performance of the trained network. and we compute the PSNR between the denoised images and the clean ground truth images.
trainer.test(test_dataloader, metrics=dinv.metric.PSNR())

/local/jtachell/deepinv/deepinv/deepinv/training/trainer.py:1548: UserWarning: non_blocking_transfers=True but DataLoader.pin_memory=False; set pin_memory=True to overlap host-device copies with compute.
self.setup_train(train=False)
Eval epoch 0: TotalLoss=0.067, PSNR=23.969, PSNR no learning=19.487
Test results:
PSNR no learning: 19.487 +- 1.628
PSNR: 23.969 +- 1.144
{'PSNR no learning': 19.487266845703125, 'PSNR no learning_std': 1.6277921401540443, 'PSNR': 23.96924446105957, 'PSNR_std': 1.1435920934150428}
- References:
Total running time of the script: (0 minutes 7.257 seconds)