
Note
New to DeepInverse? Get started with the basics with the 5 minute quickstart tutorial..
Vanilla Unfolded algorithm for super-resolution#
This is a simple example to show how to use vanilla unfolded Plug-and-Play. The DnCNN denoiser and the algorithm parameters (stepsize, regularization parameters) are trained jointly. For simplicity, we show how to train the algorithm on a small dataset. For optimal results, use a larger dataset.
import deepinv as dinv
import torch
from deepinv.models.utils import get_weights_url
from torch.utils.data import DataLoader
from deepinv.optim.data_fidelity import L2
from deepinv.optim.prior import PnP
from deepinv.optim import DRS
from torchvision import transforms
from deepinv.utils import get_cache_home
from deepinv.datasets import BSDS500
Setup paths for data loading and results.#
BASE_DIR = get_cache_home() / "demo_unfolded_sr"
DATA_DIR = BASE_DIR / "measurements"
RESULTS_DIR = BASE_DIR / "results"
CKPT_DIR = BASE_DIR / "ckpts"
# Set the global random seed from pytorch to ensure reproducibility of the example.
torch.manual_seed(0)
device = dinv.utils.get_device()
Selected GPU 0 with 8069.25 MiB free memory
Load base image datasets and degradation operators.#
In this example, we use the CBSD500 dataset for training and the Set3C dataset for testing.
img_size = 64 if torch.cuda.is_available() else 32
n_channels = 3 # 3 for color images, 1 for gray-scale images
operation = "super-resolution"
Generate a dataset of low resolution images and load it.#
We use the Downsampling class from the physics module to generate a dataset of low resolution images.
# For simplicity, we use a small dataset for training.
# To be replaced for optimal results. For example, you can use the larger DIV2K or LSDIR datasets (also provided in the library).
# Specify the train and test transforms to be applied to the input images.
test_transform = transforms.Compose(
[transforms.CenterCrop(img_size), transforms.ToTensor()]
)
train_transform = transforms.Compose(
[transforms.RandomCrop(img_size), transforms.ToTensor()]
)
# Define the base train and test datasets of clean images.
train_base_dataset = BSDS500(download=True, train=True, transform=train_transform)
test_base_dataset = BSDS500(download=False, train=False, transform=test_transform)
# Use parallel dataloader if using a GPU to speed up training, otherwise, as all computes are on CPU, use synchronous
# dataloading.
num_workers = 4 if torch.cuda.is_available() else 0
# Degradation parameters
factor = 2
noise_level_img = 0.03
# Generate the gaussian blur downsampling operator.
physics = dinv.physics.Downsampling(
filter="gaussian",
img_size=(n_channels, img_size, img_size),
factor=factor,
device=device,
noise_model=dinv.physics.GaussianNoise(sigma=noise_level_img),
)
my_dataset_name = "demo_unfolded_sr"
n_images_max = (
None if torch.cuda.is_available() else 10
) # max number of images used for training (use all if you have a GPU)
measurement_dir = DATA_DIR / "BSDS500" / operation
generated_datasets_path = dinv.datasets.generate_dataset(
train_dataset=train_base_dataset,
test_dataset=test_base_dataset,
physics=physics,
device=device,
save_dir=measurement_dir,
train_datapoints=n_images_max,
num_workers=num_workers,
dataset_filename=str(my_dataset_name),
)
train_dataset = dinv.datasets.HDF5Dataset(path=generated_datasets_path, train=True)
test_dataset = dinv.datasets.HDF5Dataset(path=generated_datasets_path, train=False)
/local/jtachell/deepinv/deepinv/deepinv/datasets/datagenerator.py:600: UserWarning: Dataset /local/jtachell/.cache/deepinv/demo_unfolded_sr/measurements/BSDS500/super-resolution/demo_unfolded_sr0.h5 already exists, this will close and overwrite the previous dataset.
warn(
Dataset has been saved at /local/jtachell/.cache/deepinv/demo_unfolded_sr/measurements/BSDS500/super-resolution/demo_unfolded_sr0.h5
Define the unfolded PnP algorithm.#
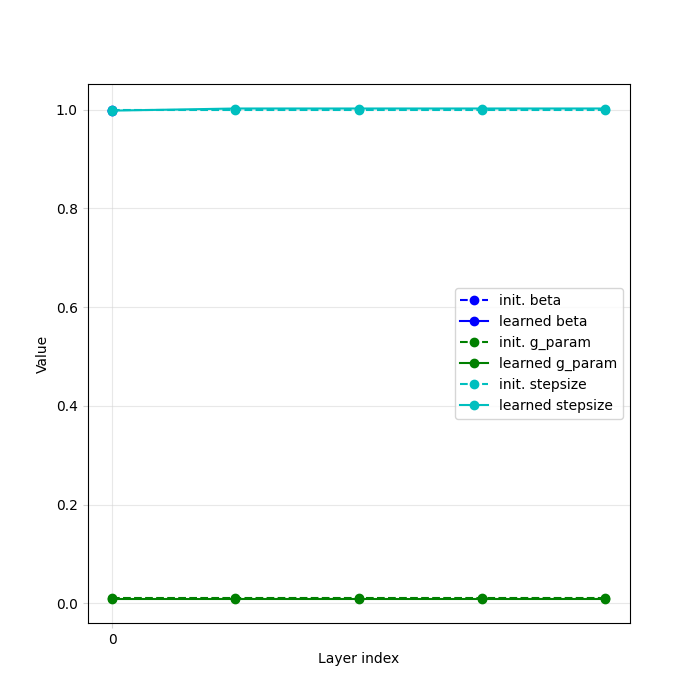
The chosen algorithm is here DRS (Douglas-Rachford Splitting). Note that if the prior (resp. a parameter) is initialized with a list of length max_iter, then a distinct model (resp. parameter) is trained for each iteration. For fixed trained model prior (resp. parameter) across iterations, initialize with a single element.
# Unrolled optimization algorithm parameters
max_iter = 5 # number of unfolded layers
# Select the data fidelity term
data_fidelity = L2()
# Set up the trainable denoising prior
# Here the prior model is common for all iterations
prior = PnP(denoiser=dinv.models.DnCNN(depth=20, pretrained="download").to(device))
# The parameters are initialized with a list of length max_iter, so that a distinct parameter is trained for each iteration.
stepsize = [1.0] * max_iter # stepsize of the algorithm
sigma_denoiser = [
1.0
] * max_iter # noise level parameter of the denoiser (not used by DnCNN)
beta = 1.0 # relaxation parameter of the Douglas-Rachford splitting
trainable_params = [
"stepsize",
"beta",
"sigma_denoiser",
] # define which parameters are trainable
# Logging parameters
verbose = True
# Define the unfolded trainable model.
model = DRS(
stepsize=stepsize,
sigma_denoiser=sigma_denoiser,
beta=beta,
trainable_params=trainable_params,
data_fidelity=data_fidelity,
max_iter=max_iter,
prior=prior,
unfold=True,
)
Define the training parameters.#
We use the Adam optimizer and the StepLR scheduler.
# training parameters
epochs = 5 if torch.cuda.is_available() else 1
learning_rate = 5e-4
train_batch_size = 32 if torch.cuda.is_available() else 1
test_batch_size = 3
# choose optimizer and scheduler
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate, weight_decay=1e-8)
# If working on CPU, start with a pretrained model to reduce training time
if not torch.cuda.is_available():
file_name = "demo_vanilla_unfolded.pth"
url = get_weights_url(model_name="demo", file_name=file_name)
ckpt = torch.hub.load_state_dict_from_url(
url, map_location=lambda storage, loc: storage, file_name=file_name
)
model.load_state_dict(ckpt["state_dict"])
optimizer.load_state_dict(ckpt["optimizer"])
# choose supervised training loss
losses = [dinv.loss.SupLoss(metric=dinv.metric.MSE())]
train_dataloader = DataLoader(
train_dataset, batch_size=train_batch_size, num_workers=num_workers, shuffle=True
)
test_dataloader = DataLoader(
test_dataset, batch_size=test_batch_size, num_workers=num_workers, shuffle=False
)
Train the network#
We train the network using the deepinv.Trainer class.
trainer = dinv.Trainer(
model,
physics=physics,
train_dataloader=train_dataloader,
eval_dataloader=test_dataloader,
epochs=epochs,
losses=losses,
optimizer=optimizer,
device=device,
early_stop=True, # set to None to disable early stopping
save_path=str(CKPT_DIR / operation),
verbose=verbose,
show_progress_bar=False, # disable progress bar for better vis in sphinx gallery.
)
model = trainer.train()
/local/jtachell/deepinv/deepinv/deepinv/training/trainer.py:1356: UserWarning: non_blocking_transfers=True but DataLoader.pin_memory=False; set pin_memory=True to overlap host-device copies with compute.
self.setup_train()
The model has 668238 trainable parameters
/local/jtachell/deepinv/deepinv/deepinv/training/trainer.py:521: UserWarning: early_stop should be an integer or None. Setting early_stop=3. This behaviour will be deprecated in future versions.
warnings.warn(
Train epoch 0: TotalLoss=0.009, PSNR=21.589
Eval epoch 0: PSNR=20.575
Best model saved at epoch 1
Train epoch 1: TotalLoss=0.007, PSNR=23.018
Eval epoch 1: PSNR=21.435
Best model saved at epoch 2
Train epoch 2: TotalLoss=0.007, PSNR=23.383
Eval epoch 2: PSNR=21.461
Best model saved at epoch 3
Train epoch 3: TotalLoss=0.006, PSNR=23.749
Eval epoch 3: PSNR=21.659
Best model saved at epoch 4
Train epoch 4: TotalLoss=0.006, PSNR=23.943
Eval epoch 4: PSNR=21.535
Test the network#
trainer.test(test_dataloader)
test_sample, _ = next(iter(test_dataloader))
model.eval()
test_sample = test_sample.to(device)
# Get the measurements and the ground truth
y = physics(test_sample)
with torch.no_grad():
rec = model(y, physics=physics)
backprojected = physics.A_adjoint(y)
dinv.utils.plot(
[backprojected, rec, test_sample],
titles=["Linear", "Reconstruction", "Ground truth"],
suptitle="Reconstruction results",
)
/local/jtachell/deepinv/deepinv/deepinv/training/trainer.py:1548: UserWarning: non_blocking_transfers=True but DataLoader.pin_memory=False; set pin_memory=True to overlap host-device copies with compute.
self.setup_train(train=False)
Eval epoch 0: PSNR=21.535, PSNR no learning=9.122
Test results:
PSNR no learning: 9.122 +- 2.903
PSNR: 21.535 +- 3.457
/local/jtachell/deepinv/deepinv/deepinv/utils/plotting.py:408: UserWarning: This figure was using a layout engine that is incompatible with subplots_adjust and/or tight_layout; not calling subplots_adjust.
fig.subplots_adjust(top=0.75)
Total running time of the script: (0 minutes 50.251 seconds)