Trainer#
- class deepinv.Trainer(model, physics, optimizer, train_dataloader, ...)[source]#
Bases:
objectTrainer class for training a reconstruction network.
See also
See the User Guide for more details and for how to adapt the trainer to your needs.
See Training a reconstruction model for a simple example of how to use the trainer.
Training can be done by calling the
deepinv.Trainer.train()method, whereas testing can be done by calling thedeepinv.Trainer.test()method.
Tip
The training code can synchronize with MLOps tools like Weights & Biases and MLflow for logging and visualization by setting
wandb_vis=Trueormlflow_vis=True.Parameters are described below, grouped into Basics, Optimization, Evaluation, Physics Generators, Model Saving, Comparing with Pseudoinverse Baseline, Plotting, Verbose and Weights & Biases.
- Basics:
The dataloaders should return data in the correct format for DeepInverse: see datasets user guide for how to use predefined datasets, create datasets, or generate datasets. These will be checked automatically with
deepinv.datasets.check_dataset().If the dataloaders do not return measurements
y, then you should use theonline_measurements=Trueoption which generates measurements in an online manner (optionally with parameters), running under the hoody=physics(x)ory=physics(x, **params). Otherwise if dataloaders do return measurementsy, setonline_measurements=False(default) otherwiseywill be ignored and new measurements will be generated online.Tip
If your dataloaders do not return
ybut you do not want online measurements, usedeepinv.datasets.generate_dataset()to generate a dataset of offline measurements from a dataset ofxand aphysics.- Parameters:
model (deepinv.models.Reconstructor, torch.nn.Module) – Reconstruction network, which can be any reconstruction network. or any other custom reconstruction network.
physics (deepinv.physics.Physics, list[deepinv.physics.Physics]) – Forward operator(s).
train_dataloader (torch.utils.data.DataLoader, list[torch.utils.data.DataLoader]) – Train data loader(s), see datasets user guide for how we expect data to be provided.
online_measurements (bool) – Generate new measurements
yin an online manner at each iteration by callingy=physics(x). IfFalse(default), the measurements are loaded from the training dataset.device (str, torch.device) – Device on which to run the training (e.g., ‘cuda’, ‘mps’ or ‘cpu’). Default is first ‘cuda’ and second ‘mps’ if available, otherwise ‘cpu’.
- Optimization:
- Parameters:
optimizer (None, torch.optim.Optimizer) – Torch optimizer for training the network. Default is
None.epochs (int) – Number of training epochs. Default is 100. The trainer will perform gradient steps equal to the
min(epochs*n_batches, max_batch_steps).max_batch_steps (int) – Number of gradient steps per iteration. Default is
1e10. The trainer will perform batch steps equal to themin(epochs*n_batches, max_batch_steps).scheduler (None, torch.optim.lr_scheduler.LRScheduler) – Torch scheduler for changing the learning rate across iterations. Default is
None.losses (deepinv.loss.Loss, list[deepinv.loss.Loss]) – Loss or list of losses used for training the model. Optionally wrap losses using a loss scheduler for more advanced training. See the libraries’ training losses. Where relevant, the underlying metric should have
reduction=Noneas we perform the averaging usingdeepinv.utils.AverageMeterto deal with uneven batch sizes. Default issupervised loss.grad_clip (float) – Gradient clipping value for the optimizer. If None, no gradient clipping is performed. Default is None.
optimizer_step_multi_dataset (bool) – If
True, the optimizer step is performed once on all datasets. IfFalse, the optimizer step is performed on each dataset separately.
Note
The losses and evaluation metrics can be chosen from our training losses or our metrics
Custom losses can be used, as long as it takes as input
(x, x_net, y, physics, model)and returns a tensor of lengthbatch_size(i.e.reduction=Nonein the underlying metric, as we perform averaging to deal with uneven batch sizes), wherexis the ground truth,x_netis the network reconstruction \(\inversef{y}{A}\),yis the measurement vector,physicsis the forward operator andmodelis the reconstruction network. Note that not all inputs need to be used by the loss, e.g., self-supervised losses will not make use ofx.Custom metrics can also be used in the exact same way as custom losses.
- Evaluation:
Note
Supervised evaluation: If ground-truth data is available for validation, use any full reference metric, e.g.
PSNR.Self-supervised evaluation: If no ground-truth data is available for validation, it is still possible to validate using:
no reference metrics, e.g.
NIQEself-supervised losses with
compute_eval_losses=Trueandmetrics=None.Additionally, in this case, we recommend setting
compute_train_metrics=Falseto avoid computing metrics inmodel.train()mode. This is required by many self-supervised losses, such asSplittingLossorR2RLoss, which behave differently inmodel.train()andmodel.eval()modes.For early-stopping with self-supervised losses,
early_stop_on_lossesmust also beTrue.
- Parameters:
eval_dataloader (None, torch.utils.data.DataLoader, list[torch.utils.data.DataLoader]) – Evaluation data loader(s), see datasets user guide for how we expect data to be provided.
metrics (Metric, list[Metric], None) – Metric or list of metrics used for evaluating the model. They should have
reduction=Noneas we perform the averaging usingdeepinv.utils.AverageMeterto deal with uneven batch sizes. See the libraries’ evaluation metrics. Default isPSNR.eval_interval (int) – Number of epochs (or train iters, if
log_train_batch=True) between each evaluation of the model on the evaluation set. Default is1.compute_train_metrics (bool) –
If
False, do not compute metrics during training on train set. IfTrue(default), during training all metrics are computed on the training dataloader.Warning
If
compute_train_metrics=Truethe metrics are computed using the model prediction during training (i.e., inmodel.train()mode) to avoid an additional forward pass. This can lead to metrics that are different at test time when the model is inmodel.eval()mode, and/or produce errors if the network does not provide the same output shapes under train and eval modes (e.g., which is the case ofsome self-supervised losses).compute_eval_losses (bool) – If
True, the losses are computed during evaluation. Default isFalse. This is useful when using self-supervised losses for evaluation and early-stopping or to make sure that the model is performing similarly on losses on the train and eval sets.early_stop (None, int) – If not
None, the training stops when the first evaluation metric is not improving afterearly_stoppasses over the eval dataset. Default isNone(no early stopping). The user can modify the strategy for saving the best model by overriding thedeepinv.Trainer.stop_criterion()method.early_stop_on_losses (bool) – Early stop using losses computed on the eval set instead of metrics: useful for stopping when using a self-supervised loss or when ground truth is unavailable. Default is
False. IfTrue, requirescompute_eval_lossesto beTrue.log_train_batch (bool) – if
True, log train batch and eval-set metrics and losses for each train batch during training. This is useful for visualizing train progress inside an epoch, not just over epochs. IfFalse(default), log average over dataset per epoch (standard training).
Tip
If a validation dataloader
eval_dataloaderis provided, the trainer will also save the best model according to the first metric in the list, using the following format:save_path/yyyy-mm-dd_hh-mm-ss/ckp_best.pth.tar. The user can modify the strategy for saving the best model by overriding thedeepinv.Trainer.save_best_model()method. The best model can be also loaded using thedeepinv.Trainer.load_best_model()method.
- Physics Generators:
- Parameters:
physics_generator (None, deepinv.physics.generator.PhysicsGenerator) – Optional physics generator for generating the physics operators. If not
None, the physics operators are randomly sampled at each iteration using the generator. Should be used in conjunction withonline_measurements=True, no effect whenonline_measurements=False. Also seeloop_random_online_physics. Default isNone.loop_random_online_physics (bool) – if
True, resets the physics generator and noise model back to its initial state at the beginning of each epoch, so that the same measurements are generated each epoch. Requiresshuffle=Falsein dataloaders. IfFalse, generates new physics every epoch. Used in conjunction withonline_measurements=Trueandphysics_generatoror noise model inphysics, no effect whenonline_measurements=False. Default isFalse.
Warning
If the physics changes at each iteration for online measurements (e.g. if
physics_generatoris used to generate random physics operators or noise model is used), the generated measurements will randomly vary each epoch. If this is not desired (i.e. you want the same online measurements each epoch), setloop_random_online_physics=True. This resets the physics generator and noise model’s random generators every epoch.Caveat: this requires
shuffle=Falsein your dataloaders.An alternative, safer solution is to generate and save params offline using
deepinv.datasets.generate_dataset(). The params dict will then be automatically updated every time data is loaded.
- Model Saving:
- Parameters:
Training details are saved every
ckp_intervalepochs in the following formatsave_path/yyyy-mm-dd_hh-mm-ss/ckp_{epoch}.pth.tar
where
.pth.tarfile contains a dictionary with the keys:epoch: current epoch number when savedstate_dict: model parameters state dictionaryloss: loss history on train settrain_metrics: metric history on train seteval_loss: loss history on eval seteval_metrics: metric history on eval setoptimizer: optimizer state dictionary, orNoneif not usedscheduler: learning rate scheduler state dictionary, orNoneif not used
- Comparison with Pseudoinverse Baseline:
- Parameters:
compare_no_learning (bool) – If
True, the no learning method is compared to the network reconstruction. Default isFalse.no_learning_method (str, Reconstructor) – Reconstruction method used for the no learning comparison. Options are
'A_dagger','A_adjoint','prox_l2', or'y'. Default is'A_dagger'. The user can also provide a custom method by overriding theno_learning_inferencemethod. Default is'A_adjoint'.
- Plotting:
- Parameters:
plot_images (bool) – Plots reconstructions every
ckp_intervalepochs. Default isFalse.plot_measurements (bool) – Plot the measurements y, default is
True.plot_convergence_metrics (bool) – Plot convergence metrics for model, default is
False.rescale_mode (str) – Rescale mode for plotting images. Default is
'clip'.
- Verbose:
- Parameters:
verbose (bool) – Output training progress information in the console. Default is
True.verbose_individual_losses (bool) – Deprecated. This parameter is deprecated and will be removed in a future version. Individual losses are now always added to logs when multiple losses are present. Default is
None.show_progress_bar (bool) – Show a progress bar during training. Default is
True.freq_update_progress_bar (int) – progress bar postfix update frequency (measured in iterations). Defaults to 1. Increasing this may speed up training.
check_grad (bool) – Compute and print the gradient norm at each iteration. Default is
False.
- Weights & Biases:
- Parameters:
wandb_vis (bool) – Logs data onto Weights & Biases, see https://wandb.ai/ for more details. Default is
False.wandb_setup (dict) – Dictionary with the setup for wandb, see https://docs.wandb.ai/quickstart for more details. Default is
{}.plot_interval (int) – Frequency of plotting images to MLOps tools (wandb or MLflow) during evaluation (at the end of each epoch). If
1, plots at each epoch. Default is1.freq_plot (int) – deprecated. Use
plot_interval
- MLflow:
- Parameters:
mlflow_vis (bool) – Logs data onto MLflow, see https://mlflow.org/ for more details. Default is
False.mlflow_setup (dict) – Dictionary with the setup for mlflow, see https://www.mlflow.org/docs/latest/python_api/mlflow.html#mlflow.start_run for more details. Default is
{}.non_blocking_transfers (bool) – Use non-blocking host-to-device transfers for data loading. Default is
True. It is advised to enable pinned memory in the dataloader when using this option for best performance.
- compute_loss(physics, x, y, train=True, epoch=None, step=False)[source]#
Compute the loss and perform the backward pass.
It evaluates the reconstruction network, computes the losses, and performs the backward pass.
- Parameters:
physics (deepinv.physics.Physics) – Current physics operator.
x (torch.Tensor) – Ground truth.
y (torch.Tensor) – Measurement.
train (bool) – If
True, the model is trained, otherwise it is evaluated.epoch (int) – current epoch.
step (bool) – Whether to perform an optimization step when computing the loss.
- Returns:
(tuple) The network reconstruction x_net (for plotting and computing metrics) and the logs (for printing the training progress).
- compute_metrics(x, x_net, y, physics, logs, train=True, epoch=None)[source]#
Compute the metrics.
It computes the metrics over the batch.
- Parameters:
x (torch.Tensor) – Ground truth.
x_net (torch.Tensor) – Network reconstruction.
y (torch.Tensor) – Measurement.
physics (deepinv.physics.Physics) – Current physics operator.
logs (dict) – Dictionary containing the logs for printing the training progress.
train (bool) – If
True, the model is trained, otherwise it is evaluated.epoch (int) – current epoch.
- Returns:
The reconstructed signal during eval (if
x_net=None) and the logs with the metrics
- get_samples(iterators, g)[source]#
Get the samples.
This function returns a dictionary containing necessary data for the model inference. It needs to contain the measurement, the ground truth, and the current physics operator, but can also contain additional data.
- get_samples_offline(iterators, g)[source]#
Get the samples for the offline measurements.
In this setting, samples have been generated offline and are loaded from the dataloader. This function returns a tuple containing necessary data for the model inference. It needs to contain the measurement, the ground truth, and the current physics operator, but can also contain additional data (you can override this function to add custom data).
If the dataloader returns 3-tuples, this is assumed to be
(x, y, params)whereparamsis a dict of physics generator params. These params are then used to update the physics.
- get_samples_online(iterators, g)[source]#
Get the samples for the online measurements.
In this setting, a new sample is generated at each iteration by calling the physics operator. This function returns a dictionary containing necessary data for the model inference. It needs to contain the measurement, the ground truth, and the current physics operator, but can also contain additional data.
- load_best_model()[source]#
Load the best model.
It loads the model from the checkpoint saved during training.
- Returns:
The model.
- log_metrics_mlops(logs, step, train=True)[source]#
Log the metrics to MLOps tools including wandb and MLflow.
It logs the metrics to wandb and MLflow.
- log_metrics_wandb(logs, step, train=True)[source]#
This method is deprecated and will be removed in a future release. Instead, use
log_metrics_mlops().
- model_inference(y, physics, x=None, train=True, **kwargs)[source]#
Perform the model inference.
It returns the network reconstruction given the samples.
- Parameters:
y (torch.Tensor) – Measurement.
physics (deepinv.physics.Physics) – Current physics operator.
x (torch.Tensor) – Optional ground truth, used for computing convergence metrics.
- Returns:
The network reconstruction.
- no_learning_inference(y, physics)[source]#
Perform the no learning inference.
By default it returns the (linear) pseudo-inverse reconstruction given the measurement.
- Parameters:
y (torch.Tensor) – Measurement.
physics (deepinv.physics.Physics) – Current physics operator.
- Returns:
Reconstructed image.
- plot(epoch, physics, x, y, x_net, train=True)[source]#
Plot ground truths, measurements and reconstructions and at test time, optionally save them.
Note
Images can be saved to disk at test time by providing a value for the parameter
save_folder_imwhen calling the methoddeepinv.Trainer.test(). Note that in that case, every test sample is saved and not only the first ones.- Parameters:
epoch (int) – Current epoch.
physics (deepinv.physics.Physics) – Current physics operator.
x (torch.Tensor) – Ground truth.
y (torch.Tensor) – Measurement.
x_net (torch.Tensor) – Network reconstruction.
train (bool) – If
True, the model is trained, otherwise it is evaluated.
- save_best_model(epoch, train_ite, **kwargs)[source]#
Save the best model using validation metrics.
By default, uses validation based on first metric. If no metric is provided (e.g. in self-supervised learning), uses the first loss on the eval dataset instead (requires having
compute_eval_losses=True).Override this method to provide custom criterion.
- save_model(filename, epoch, state=None)[source]#
Save the model.
It saves the model every
ckp_intervalepochs.
- setup_train(train=True, **kwargs)[source]#
Set up the training process.
It initializes the wandb logging, the different metrics, the save path, the physics and dataloaders, and the pretrained checkpoint if given.
- Parameters:
train (bool) – whether model is being trained.
- step(epoch, progress_bar, train_ite=None, train=True, last_batch=False, update_progress_bar=False)[source]#
Train/Eval a batch.
It performs the forward pass, the backward pass, and the evaluation at each iteration.
- Parameters:
epoch (int) – Current epoch.
progress_bar – tqdm progress bar.
train_ite (int) – train iteration, only needed for logging if
Trainer.log_train_batch=Truetrain (bool) – If
True, the model is trained, otherwise it is evaluated.last_batch (bool) – If
True, the last batch of the epoch is being processed.
- Returns:
The current physics operator, the ground truth, the measurement, and the network reconstruction.
- stop_criterion(epoch, train_ite, **kwargs)[source]#
Stop criterion for early stopping.
By default, stops optimization when first eval metric doesn’t improve in the last 3 evaluations.
If
early_stop_on_losses=True(default isFalse) uses the first loss on the eval dataset instead (requires havingcompute_eval_losses=True).Override this method to early stop on a custom condition.
- Parameters:
epoch (int) – Current epoch.
train_ite (int) – Current training batch iteration, equal to (current epoch \(\times\) number of batches) + current batch within epoch
metric_history (dict) – Dictionary containing the metrics history, with the metric name as key.
metrics (list) – List of metrics used for evaluation.
- test(test_dataloader, save_path=None, compare_no_learning=True, log_raw_metrics=False, metrics=None)[source]#
Test the model, compute metrics and plot images.
Note
It is possible to save the reconstructed images along with the ground truths and measurements by specifying a value for the parameter
save_path. Note that in this case, every test sample is saved and not only the first ones.- Parameters:
test_dataloader (torch.utils.data.DataLoader, list[torch.utils.data.DataLoader]) – Test data loader(s), see datasets user guide for how we expect data to be provided.
save_path (str) – Path to the directory where to save the plotted images if desired (optional).
compare_no_learning (bool) – If
True, the linear reconstruction is compared to the network reconstruction.log_raw_metrics (bool) – if
True, also return non-aggregated metrics as a list.metrics (Metric, list[Metric], None) – Metric or list of metrics used for evaluation. If
None, uses the metrics provided during Trainer initialization.
- Returns:
dict of metrics results with means and stds.
- Return type:
Examples using Trainer:#

Imaging inverse problems with adversarial networks

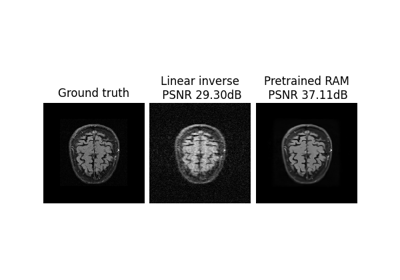
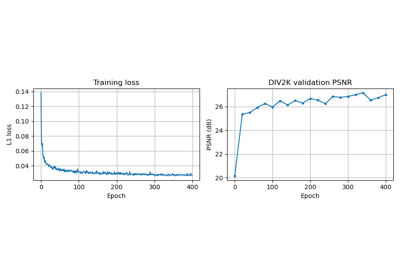

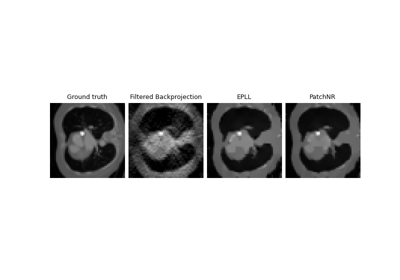
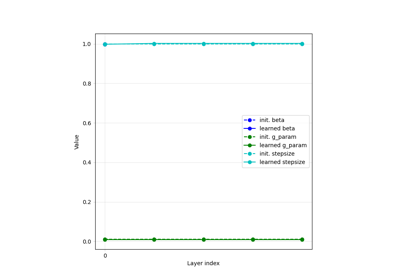
Patch priors for limited-angle computed tomography

Self-supervised MRI reconstruction with Artifact2Artifact
Self-supervised learning with Equivariant Imaging for MRI.

Self-supervised learning with Equivariant Splitting

Self-supervised learning from incomplete measurements of multiple operators.

Self-supervised denoising with the Neighbor2Neighbor loss.

Self-supervised denoising with the Generalized R2R loss.
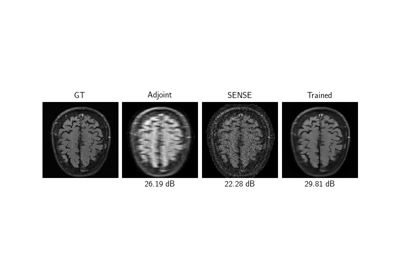

Self-supervised learning with measurement splitting



Deep Equilibrium (DEQ) algorithms for image deblurring

Learned Iterative Soft-Thresholding Algorithm (LISTA) for compressed sensing

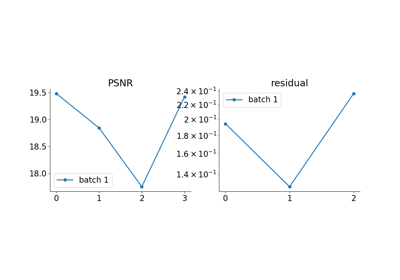
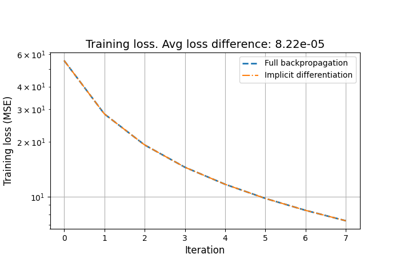
Reducing the memory and computational complexity of unfolded network training

Unfolded Chambolle-Pock for constrained image inpainting