
Note
New to DeepInverse? Get started with the basics with the 5 minute quickstart tutorial..
Flow-Matching for posterior sampling and unconditional generation#
This demo shows you how to perform unconditional image generation and posterior sampling using Flow Matching (FM).
Flow matching consists in building a continuous transportation between a reference distribution \(p_1\) which is easy to sample from (e.g., a Gaussian distribution) and the data distribution \(p_0\). Sampling is done by solving the following ordinary differential equation (ODE) defined by a time-dependent velocity field \(v_\theta(x,t)\):
The velocity field \(v_\theta(x,t)\) is typically trained to approximate the conditional expectation:
where \(a(t)\) and \(b(t)\) are interpolation coefficients such that \(x_t\) interpolates between \(x_0\) and \(x_1\). When the reference distribution \(p_0\) is the standard Gaussian, the velocity field can be expressed as a function of a Gaussian denoiser \(D(x, \sigma)\) as follows:
The most common choice of time schedulers is the linear schedule \(a(t) = 1 - t\) and \(b(t) = t\).
In this demo, we will show how to :
Perform unconditional generation using, instead of a trained denoiser, the closed-form MMSE denoiser
Given a dataset of clean images, it can be computed by evaluating the distance between the input image and all the points of the dataset (see deepinv.models.MMSE).
Perform posterior sampling using Flow-Matching combined with a DPS data fidelity term (see Building your diffusion posterior sampling method using SDEs for more details)
Explore different choices of time schedulers \(a(t)\) and \(b(t)\).
import torch
import deepinv as dinv
from deepinv.sampling import (
PosteriorDiffusion,
DPSDataFidelity,
EulerSolver,
FlowMatching,
)
import numpy as np
from torchvision import datasets, transforms
from deepinv.models import MMSE

We start by working with the closed-form MMSE denoser. It is calculated by computing the distance between the input image and all the points of the dataset. This can be quite long to compute for large images and large datasets. In this toy example, we use the validation set of MNIST. When using this closed-form MMSE denoiser, the sampling is guaranteed to output an image of the dataset.
device = dinv.utils.get_device()
dtype = torch.float32
figsize = 2.5
# We use the closed-form MMSE denoiser defined using as atoms the testset of MNIST.
# The deepinv MMSE denoiser takes as input a dataloader.
dataset = datasets.MNIST(
root=".", train=False, download=True, transform=transforms.ToTensor()
)
dataloader = torch.utils.data.DataLoader(dataset, batch_size=1000, shuffle=False)
n_max = (
1000 # limit the number of images to speed up the computation of the MMSE denoiser
)
tensors = torch.cat([data[0] for data in iter(dataloader)], dim=0) # (N,1,28,28)
tensors = tensors[:n_max].to(device)
denoiser = MMSE(dataloader=tensors, device=device, dtype=dtype)
Selected GPU 0 with 4759.25 MiB free memory
0%| | 0.00/9.91M [00:00<?, ?B/s]
1%| | 98.3k/9.91M [00:00<00:18, 542kB/s]
4%|▎ | 360k/9.91M [00:00<00:07, 1.27MB/s]
8%|▊ | 786k/9.91M [00:00<00:04, 2.04MB/s]
25%|██▌ | 2.49M/9.91M [00:00<00:01, 4.33MB/s]
55%|█████▍ | 5.44M/9.91M [00:00<00:00, 7.83MB/s]
95%|█████████▍| 9.40M/9.91M [00:01<00:00, 13.6MB/s]
100%|██████████| 9.91M/9.91M [00:01<00:00, 9.21MB/s]
0%| | 0.00/28.9k [00:00<?, ?B/s]
100%|██████████| 28.9k/28.9k [00:00<00:00, 319kB/s]
0%| | 0.00/1.65M [00:00<?, ?B/s]
4%|▍ | 65.5k/1.65M [00:00<00:04, 362kB/s]
22%|██▏ | 360k/1.65M [00:00<00:01, 1.11MB/s]
89%|████████▉ | 1.47M/1.65M [00:00<00:00, 3.89MB/s]
100%|██████████| 1.65M/1.65M [00:00<00:00, 3.03MB/s]
0%| | 0.00/4.54k [00:00<?, ?B/s]
100%|██████████| 4.54k/4.54k [00:00<00:00, 15.3MB/s]
The FlowMatching module deepinv.sampling.FlowMatching uses by default the following schedules: \(a_t=1-t\), \(b_t=t\).
The module FlowMatching module takes as input the denoiser and the ODE solver.
num_steps = 100
timesteps = torch.linspace(0.99, 0.0, num_steps)
rng = torch.Generator(device).manual_seed(5)
solver = EulerSolver(timesteps=timesteps, rng=rng)
sde = FlowMatching(denoiser=denoiser, solver=solver, device=device, dtype=dtype)
sample, trajectory = sde(
x_init=(1, 1, 28, 28),
seed=0,
get_trajectory=True,
)
dinv.utils.plot(
sample,
titles="Unconditional FM generation",
save_fn="FM_sample.png",
figsize=(figsize, figsize),
)
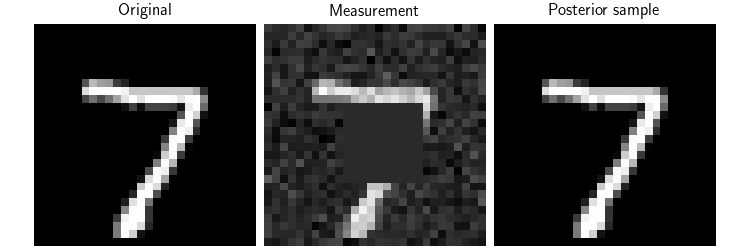
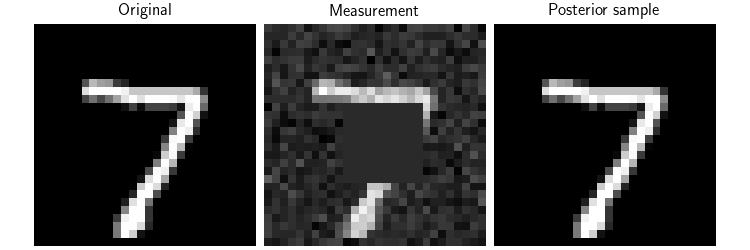
Now, we can use the Flow-Matching model to perform posterior sampling.
We consider the inpainting problem, where we have a masked image and we want to recover the original image.
We use DPS deepinv.sampling.DPSDataFidelity as data fidelity term (see Building your diffusion posterior sampling method using SDEs for more details).
Note that due to the division by \(a(t)\) in the velocity field, initialization close to t=1 causes instability.
x = next(iter(dataloader))[0][:1].to(device)
mask = torch.ones_like(x)
mask[..., 10:20, 10:20] = 0.0
physics = dinv.physics.Inpainting(
img_size=x.shape[1:],
mask=mask,
device=device,
noise_model=dinv.physics.GaussianNoise(sigma=0.1),
)
y = physics(x)
dps_fidelity = DPSDataFidelity(denoiser=denoiser, weight=1.0)
model = PosteriorDiffusion(
data_fidelity=dps_fidelity,
sde=sde,
solver=solver,
dtype=dtype,
device=device,
verbose=True,
)
x_hat, trajectory = model(
y,
physics,
x_init=None,
get_trajectory=True,
seed=0,
)
# Here, we plot the original image, the measurement and the posterior sample
dinv.utils.plot(
[x, y, x_hat],
show=True,
titles=["Original", "Measurement", "Posterior sample"],
figsize=(figsize * 3, figsize),
save_fn="FM_posterior.png",
)
0%| | 0/99 [00:00<?, ?it/s]
18%|█▊ | 18/99 [00:00<00:00, 175.03it/s]
36%|███▋ | 36/99 [00:00<00:00, 175.75it/s]
55%|█████▍ | 54/99 [00:00<00:00, 175.57it/s]
73%|███████▎ | 72/99 [00:00<00:00, 175.87it/s]
91%|█████████ | 90/99 [00:00<00:00, 175.70it/s]
100%|██████████| 99/99 [00:00<00:00, 175.58it/s]
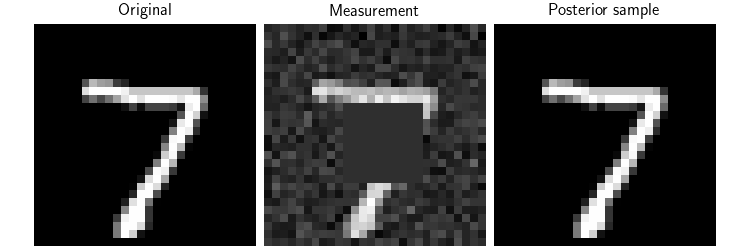
Finally, we show how to use different choices of time schedulers \(a_t\) and \(b_t\). Here, we use another typical choice of schedulers \(a_t = \cos(\frac{\pi}{2} t)\) and \(b_t = \sin(\frac{\pi}{2} t)\) which also satisfy the interpolation condition \(a_0 = 1\), \(b_0 = 0\), \(a_1 = 0\), \(b_1 = 1\). Note that, again, due to the division by \(a_t\) in the velocity field, initialization close to t=1 causes instability.
a_t = lambda t: torch.cos(np.pi / 2 * t)
a_prime_t = lambda t: -np.pi / 2 * torch.sin(np.pi / 2 * t)
b_t = lambda t: torch.sin(np.pi / 2 * t)
b_prime_t = lambda t: np.pi / 2 * torch.cos(np.pi / 2 * t)
sde = FlowMatching(
a_t=a_t,
a_prime_t=a_prime_t,
b_t=b_t,
b_prime_t=b_prime_t,
denoiser=denoiser,
solver=solver,
device=device,
dtype=dtype,
)
model = PosteriorDiffusion(
data_fidelity=dps_fidelity,
sde=sde,
solver=solver,
dtype=dtype,
device=device,
verbose=True,
)
x_hat, trajectory = model(
y,
physics,
x_init=None,
get_trajectory=True,
)
# Here, we plot the original image, the measurement and the posterior sample
dinv.utils.plot(
[x, y, x_hat],
show=True,
titles=["Original", "Measurement", "Posterior sample"],
figsize=(figsize * 3, figsize),
save_fn="FM_posterior_new_at_bt.png",
)
0%| | 0/99 [00:00<?, ?it/s]
16%|█▌ | 16/99 [00:00<00:00, 156.12it/s]
32%|███▏ | 32/99 [00:00<00:00, 157.01it/s]
48%|████▊ | 48/99 [00:00<00:00, 157.10it/s]
65%|██████▍ | 64/99 [00:00<00:00, 157.37it/s]
81%|████████ | 80/99 [00:00<00:00, 157.52it/s]
97%|█████████▋| 96/99 [00:00<00:00, 157.52it/s]
100%|██████████| 99/99 [00:00<00:00, 157.22it/s]
- References:
Total running time of the script: (0 minutes 20.679 seconds)