
Note
New to DeepInverse? Get started with the basics with the 5 minute quickstart tutorial..
Low-field MRI denoising without ground truth#
We demonstrate self-supervised (blind) denoising of a low-field MRI scan without ground truth data.
In low-field MRI, images have high noise due to the fixed permanent magnet, and acquiring clean reference images is often impossible. One could average the images over multiple repetitions, but if there’s any patient motion, the image would be blurry.
Here, we fine-tune the Reconstruct Anything Model (deepinv.models.RAM) [1] on a single noisy scan using the self-supervised
Recorrupted2Recorrupted loss [2]. Play around with different self-supervised denoising losses (see Self-Supervised Learning) and models!
Note that, if more data is available, better results can be obtained by fine-tuning on more samples.
import torch
import deepinv as dinv
device = dinv.utils.get_device()
Selected GPU 0 with 3910.25 MiB free memory
Load data#
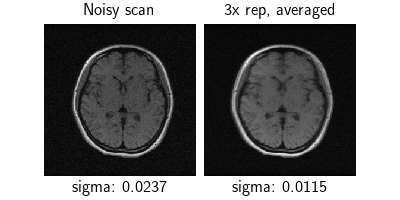
We load a single low-field T1 MRI scan (Oper 0.3T) from the M4Raw dataset [3], which contains multiple repetitions of the same scan with inter-scan motion. We use the first repetition as our noisy measurement, and average all three repetitions to create a “reference” (which is still blurry due to motion).
def open_m4raw(fname: str) -> torch.Tensor:
"""Load M4Raw slice"""
x = dinv.io.load_ismrmd(fname, data_slice=8).unsqueeze(
0
) # Load middle slice, shape 12NHW
x = dinv.utils.MRIMixin().kspace_to_im(x) # Convert to image space
x = dinv.utils.MRIMixin().rss(
x, multicoil=True
) # Root-sum-square following original paper, shape 11HW
x = dinv.utils.normalize_signal(x, mode="min_max") # Normalise to 0-1
return x
DATA_DIR = dinv.utils.get_cache_home() / "m4raw" / "motion"
DATA_DIR.mkdir(parents=True, exist_ok=True)
dinv.utils.download_example("demo_m4raw_inter-scan_motion_0.h5", DATA_DIR)
dinv.utils.download_example("demo_m4raw_inter-scan_motion_1.h5", DATA_DIR)
dinv.utils.download_example("demo_m4raw_inter-scan_motion_2.h5", DATA_DIR)
y = open_m4raw(DATA_DIR / "demo_m4raw_inter-scan_motion_0.h5")
x = torch.cat(
[
open_m4raw(DATA_DIR / "demo_m4raw_inter-scan_motion_0.h5"),
open_m4raw(DATA_DIR / "demo_m4raw_inter-scan_motion_1.h5"),
open_m4raw(DATA_DIR / "demo_m4raw_inter-scan_motion_2.h5"),
]
).mean(
dim=0, keepdim=True
) # Average 3 repetitions
Since the data is raw, we estimate the noise level in both the single scan and the averaged scan using patch covariance. Note that the averaged scan has lower noise as expected, but observe the motion blurring!
noise_estimator = dinv.models.PatchCovarianceNoiseEstimator()
dinv.utils.plot(
{"Noisy scan": y, "3x rep, averaged": x},
subtitles=[
f"sigma: {noise_estimator(y).item():.4f}",
f"sigma: {noise_estimator(x).item():.4f}",
],
)
Physics#
We define a simple denoising physics with Gaussian noise matching the estimated noise level.
with torch.no_grad():
sigma = noise_estimator(y.to(device))
physics = dinv.physics.Denoising(dinv.physics.GaussianNoise(sigma=sigma), device=device)
Zero-shot reconstruction#
First, we apply the pre-trained RAM model as a zero-shot denoiser without any training.
model = dinv.models.RAM(device=device)
with torch.no_grad():
x_net = model(y.to(device), physics)
Self-supervised fine-tuning#
We create a dataset from the single noisy scan and fine-tune RAM using the R2R loss. See the dedicated R2R example for more.
Note
We train for 50 epochs on GPU. For faster execution on CPU, set epochs to a smaller value.
dataset = dinv.datasets.TensorDataset(y=y)
trainer = dinv.Trainer(
model=model,
physics=physics,
train_dataloader=torch.utils.data.DataLoader(dataset, batch_size=1),
optimizer=torch.optim.AdamW(model.parameters(), lr=1e-5),
epochs=1 if str(device) == "cpu" else 50,
losses=dinv.loss.R2RLoss(noise_model=None),
metrics=None,
device=device,
save_path=None,
)
model = trainer.train()
model = model.eval()
/local/jtachell/deepinv/deepinv/deepinv/training/trainer.py:1337: UserWarning: non_blocking_transfers=True but DataLoader.pin_memory=False; set pin_memory=True to overlap host-device copies with compute.
self.setup_train()
The model has 35618813 trainable parameters
/local/jtachell/deepinv/deepinv/deepinv/training/trainer.py:541: UserWarning: Update progress bar frequency of 1 may slow down training on GPU. Consider setting freq_update_progress_bar > 1.
warnings.warn(
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 1/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 1/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.00361]
Train epoch 1/50: 100%|██████████| 1/1 [00:00<00:00, 1.91it/s, TotalLoss=0.00361]
Train epoch 1/50: 100%|██████████| 1/1 [00:00<00:00, 1.90it/s, TotalLoss=0.00361]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 2/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 2/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.00363]
Train epoch 2/50: 100%|██████████| 1/1 [00:00<00:00, 2.13it/s, TotalLoss=0.00363]
Train epoch 2/50: 100%|██████████| 1/1 [00:00<00:00, 2.12it/s, TotalLoss=0.00363]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 3/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 3/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.00365]
Train epoch 3/50: 100%|██████████| 1/1 [00:00<00:00, 2.31it/s, TotalLoss=0.00365]
Train epoch 3/50: 100%|██████████| 1/1 [00:00<00:00, 2.30it/s, TotalLoss=0.00365]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 4/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 4/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.00367]
Train epoch 4/50: 100%|██████████| 1/1 [00:00<00:00, 2.32it/s, TotalLoss=0.00367]
Train epoch 4/50: 100%|██████████| 1/1 [00:00<00:00, 2.32it/s, TotalLoss=0.00367]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 5/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 5/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.00364]
Train epoch 5/50: 100%|██████████| 1/1 [00:00<00:00, 2.34it/s, TotalLoss=0.00364]
Train epoch 5/50: 100%|██████████| 1/1 [00:00<00:00, 2.34it/s, TotalLoss=0.00364]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 6/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 6/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.00363]
Train epoch 6/50: 100%|██████████| 1/1 [00:00<00:00, 2.34it/s, TotalLoss=0.00363]
Train epoch 6/50: 100%|██████████| 1/1 [00:00<00:00, 2.33it/s, TotalLoss=0.00363]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 7/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 7/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.00363]
Train epoch 7/50: 100%|██████████| 1/1 [00:00<00:00, 2.33it/s, TotalLoss=0.00363]
Train epoch 7/50: 100%|██████████| 1/1 [00:00<00:00, 2.33it/s, TotalLoss=0.00363]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 8/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 8/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.00365]
Train epoch 8/50: 100%|██████████| 1/1 [00:00<00:00, 2.35it/s, TotalLoss=0.00365]
Train epoch 8/50: 100%|██████████| 1/1 [00:00<00:00, 2.34it/s, TotalLoss=0.00365]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 9/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 9/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.00364]
Train epoch 9/50: 100%|██████████| 1/1 [00:00<00:00, 2.35it/s, TotalLoss=0.00364]
Train epoch 9/50: 100%|██████████| 1/1 [00:00<00:00, 2.34it/s, TotalLoss=0.00364]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 10/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 10/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.00362]
Train epoch 10/50: 100%|██████████| 1/1 [00:00<00:00, 2.35it/s, TotalLoss=0.00362]
Train epoch 10/50: 100%|██████████| 1/1 [00:00<00:00, 2.35it/s, TotalLoss=0.00362]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 11/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 11/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.00363]
Train epoch 11/50: 100%|██████████| 1/1 [00:00<00:00, 2.34it/s, TotalLoss=0.00363]
Train epoch 11/50: 100%|██████████| 1/1 [00:00<00:00, 2.34it/s, TotalLoss=0.00363]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 12/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 12/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.00363]
Train epoch 12/50: 100%|██████████| 1/1 [00:00<00:00, 2.25it/s, TotalLoss=0.00363]
Train epoch 12/50: 100%|██████████| 1/1 [00:00<00:00, 2.25it/s, TotalLoss=0.00363]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 13/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 13/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.00362]
Train epoch 13/50: 100%|██████████| 1/1 [00:00<00:00, 2.11it/s, TotalLoss=0.00362]
Train epoch 13/50: 100%|██████████| 1/1 [00:00<00:00, 2.11it/s, TotalLoss=0.00362]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 14/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 14/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.0036]
Train epoch 14/50: 100%|██████████| 1/1 [00:00<00:00, 2.34it/s, TotalLoss=0.0036]
Train epoch 14/50: 100%|██████████| 1/1 [00:00<00:00, 2.34it/s, TotalLoss=0.0036]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 15/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 15/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.00363]
Train epoch 15/50: 100%|██████████| 1/1 [00:00<00:00, 2.35it/s, TotalLoss=0.00363]
Train epoch 15/50: 100%|██████████| 1/1 [00:00<00:00, 2.35it/s, TotalLoss=0.00363]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 16/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 16/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.00361]
Train epoch 16/50: 100%|██████████| 1/1 [00:00<00:00, 2.35it/s, TotalLoss=0.00361]
Train epoch 16/50: 100%|██████████| 1/1 [00:00<00:00, 2.35it/s, TotalLoss=0.00361]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 17/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 17/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.00361]
Train epoch 17/50: 100%|██████████| 1/1 [00:00<00:00, 2.35it/s, TotalLoss=0.00361]
Train epoch 17/50: 100%|██████████| 1/1 [00:00<00:00, 2.35it/s, TotalLoss=0.00361]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 18/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 18/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.00364]
Train epoch 18/50: 100%|██████████| 1/1 [00:00<00:00, 2.33it/s, TotalLoss=0.00364]
Train epoch 18/50: 100%|██████████| 1/1 [00:00<00:00, 2.33it/s, TotalLoss=0.00364]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 19/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 19/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.00362]
Train epoch 19/50: 100%|██████████| 1/1 [00:00<00:00, 2.19it/s, TotalLoss=0.00362]
Train epoch 19/50: 100%|██████████| 1/1 [00:00<00:00, 2.19it/s, TotalLoss=0.00362]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 20/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 20/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.00358]
Train epoch 20/50: 100%|██████████| 1/1 [00:00<00:00, 2.35it/s, TotalLoss=0.00358]
Train epoch 20/50: 100%|██████████| 1/1 [00:00<00:00, 2.35it/s, TotalLoss=0.00358]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 21/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 21/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.00362]
Train epoch 21/50: 100%|██████████| 1/1 [00:00<00:00, 2.35it/s, TotalLoss=0.00362]
Train epoch 21/50: 100%|██████████| 1/1 [00:00<00:00, 2.35it/s, TotalLoss=0.00362]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 22/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 22/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.00363]
Train epoch 22/50: 100%|██████████| 1/1 [00:00<00:00, 2.35it/s, TotalLoss=0.00363]
Train epoch 22/50: 100%|██████████| 1/1 [00:00<00:00, 2.35it/s, TotalLoss=0.00363]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 23/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 23/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.00365]
Train epoch 23/50: 100%|██████████| 1/1 [00:00<00:00, 2.35it/s, TotalLoss=0.00365]
Train epoch 23/50: 100%|██████████| 1/1 [00:00<00:00, 2.34it/s, TotalLoss=0.00365]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 24/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 24/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.00361]
Train epoch 24/50: 100%|██████████| 1/1 [00:00<00:00, 2.33it/s, TotalLoss=0.00361]
Train epoch 24/50: 100%|██████████| 1/1 [00:00<00:00, 2.33it/s, TotalLoss=0.00361]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 25/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 25/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.00361]
Train epoch 25/50: 100%|██████████| 1/1 [00:00<00:00, 2.34it/s, TotalLoss=0.00361]
Train epoch 25/50: 100%|██████████| 1/1 [00:00<00:00, 2.34it/s, TotalLoss=0.00361]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 26/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 26/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.00364]
Train epoch 26/50: 100%|██████████| 1/1 [00:00<00:00, 2.35it/s, TotalLoss=0.00364]
Train epoch 26/50: 100%|██████████| 1/1 [00:00<00:00, 2.34it/s, TotalLoss=0.00364]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 27/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 27/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.0036]
Train epoch 27/50: 100%|██████████| 1/1 [00:00<00:00, 2.32it/s, TotalLoss=0.0036]
Train epoch 27/50: 100%|██████████| 1/1 [00:00<00:00, 2.32it/s, TotalLoss=0.0036]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 28/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 28/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.00362]
Train epoch 28/50: 100%|██████████| 1/1 [00:00<00:00, 2.34it/s, TotalLoss=0.00362]
Train epoch 28/50: 100%|██████████| 1/1 [00:00<00:00, 2.34it/s, TotalLoss=0.00362]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 29/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 29/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.00365]
Train epoch 29/50: 100%|██████████| 1/1 [00:00<00:00, 2.34it/s, TotalLoss=0.00365]
Train epoch 29/50: 100%|██████████| 1/1 [00:00<00:00, 2.34it/s, TotalLoss=0.00365]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 30/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 30/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.00362]
Train epoch 30/50: 100%|██████████| 1/1 [00:00<00:00, 2.32it/s, TotalLoss=0.00362]
Train epoch 30/50: 100%|██████████| 1/1 [00:00<00:00, 2.32it/s, TotalLoss=0.00362]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 31/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 31/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.00364]
Train epoch 31/50: 100%|██████████| 1/1 [00:00<00:00, 2.34it/s, TotalLoss=0.00364]
Train epoch 31/50: 100%|██████████| 1/1 [00:00<00:00, 2.34it/s, TotalLoss=0.00364]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 32/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 32/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.00359]
Train epoch 32/50: 100%|██████████| 1/1 [00:00<00:00, 2.35it/s, TotalLoss=0.00359]
Train epoch 32/50: 100%|██████████| 1/1 [00:00<00:00, 2.34it/s, TotalLoss=0.00359]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 33/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 33/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.00363]
Train epoch 33/50: 100%|██████████| 1/1 [00:00<00:00, 2.35it/s, TotalLoss=0.00363]
Train epoch 33/50: 100%|██████████| 1/1 [00:00<00:00, 2.35it/s, TotalLoss=0.00363]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 34/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 34/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.00359]
Train epoch 34/50: 100%|██████████| 1/1 [00:00<00:00, 2.35it/s, TotalLoss=0.00359]
Train epoch 34/50: 100%|██████████| 1/1 [00:00<00:00, 2.35it/s, TotalLoss=0.00359]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 35/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 35/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.00364]
Train epoch 35/50: 100%|██████████| 1/1 [00:00<00:00, 2.34it/s, TotalLoss=0.00364]
Train epoch 35/50: 100%|██████████| 1/1 [00:00<00:00, 2.34it/s, TotalLoss=0.00364]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 36/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 36/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.0036]
Train epoch 36/50: 100%|██████████| 1/1 [00:00<00:00, 2.32it/s, TotalLoss=0.0036]
Train epoch 36/50: 100%|██████████| 1/1 [00:00<00:00, 2.32it/s, TotalLoss=0.0036]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 37/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 37/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.00364]
Train epoch 37/50: 100%|██████████| 1/1 [00:00<00:00, 2.34it/s, TotalLoss=0.00364]
Train epoch 37/50: 100%|██████████| 1/1 [00:00<00:00, 2.34it/s, TotalLoss=0.00364]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 38/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 38/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.00364]
Train epoch 38/50: 100%|██████████| 1/1 [00:00<00:00, 2.35it/s, TotalLoss=0.00364]
Train epoch 38/50: 100%|██████████| 1/1 [00:00<00:00, 2.35it/s, TotalLoss=0.00364]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 39/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 39/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.00363]
Train epoch 39/50: 100%|██████████| 1/1 [00:00<00:00, 2.35it/s, TotalLoss=0.00363]
Train epoch 39/50: 100%|██████████| 1/1 [00:00<00:00, 2.35it/s, TotalLoss=0.00363]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 40/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 40/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.00358]
Train epoch 40/50: 100%|██████████| 1/1 [00:00<00:00, 2.35it/s, TotalLoss=0.00358]
Train epoch 40/50: 100%|██████████| 1/1 [00:00<00:00, 2.35it/s, TotalLoss=0.00358]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 41/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 41/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.00358]
Train epoch 41/50: 100%|██████████| 1/1 [00:00<00:00, 2.33it/s, TotalLoss=0.00358]
Train epoch 41/50: 100%|██████████| 1/1 [00:00<00:00, 2.32it/s, TotalLoss=0.00358]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 42/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 42/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.00361]
Train epoch 42/50: 100%|██████████| 1/1 [00:00<00:00, 2.31it/s, TotalLoss=0.00361]
Train epoch 42/50: 100%|██████████| 1/1 [00:00<00:00, 2.31it/s, TotalLoss=0.00361]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 43/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 43/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.00362]
Train epoch 43/50: 100%|██████████| 1/1 [00:00<00:00, 2.34it/s, TotalLoss=0.00362]
Train epoch 43/50: 100%|██████████| 1/1 [00:00<00:00, 2.34it/s, TotalLoss=0.00362]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 44/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 44/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.00358]
Train epoch 44/50: 100%|██████████| 1/1 [00:00<00:00, 2.35it/s, TotalLoss=0.00358]
Train epoch 44/50: 100%|██████████| 1/1 [00:00<00:00, 2.35it/s, TotalLoss=0.00358]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 45/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 45/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.00363]
Train epoch 45/50: 100%|██████████| 1/1 [00:00<00:00, 2.35it/s, TotalLoss=0.00363]
Train epoch 45/50: 100%|██████████| 1/1 [00:00<00:00, 2.35it/s, TotalLoss=0.00363]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 46/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 46/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.00362]
Train epoch 46/50: 100%|██████████| 1/1 [00:00<00:00, 2.35it/s, TotalLoss=0.00362]
Train epoch 46/50: 100%|██████████| 1/1 [00:00<00:00, 2.35it/s, TotalLoss=0.00362]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 47/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 47/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.00362]
Train epoch 47/50: 100%|██████████| 1/1 [00:00<00:00, 2.34it/s, TotalLoss=0.00362]
Train epoch 47/50: 100%|██████████| 1/1 [00:00<00:00, 2.34it/s, TotalLoss=0.00362]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 48/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 48/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.0036]
Train epoch 48/50: 100%|██████████| 1/1 [00:00<00:00, 2.33it/s, TotalLoss=0.0036]
Train epoch 48/50: 100%|██████████| 1/1 [00:00<00:00, 2.33it/s, TotalLoss=0.0036]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 49/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 49/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.00358]
Train epoch 49/50: 100%|██████████| 1/1 [00:00<00:00, 2.34it/s, TotalLoss=0.00358]
Train epoch 49/50: 100%|██████████| 1/1 [00:00<00:00, 2.34it/s, TotalLoss=0.00358]
0%| | 0/1 [00:00<?, ?it/s]
Train epoch 50/50: 0%| | 0/1 [00:00<?, ?it/s]
Train epoch 50/50: 0%| | 0/1 [00:00<?, ?it/s, TotalLoss=0.00358]
Train epoch 50/50: 100%|██████████| 1/1 [00:00<00:00, 2.34it/s, TotalLoss=0.00358]
Train epoch 50/50: 100%|██████████| 1/1 [00:00<00:00, 2.34it/s, TotalLoss=0.00358]
Evaluation#
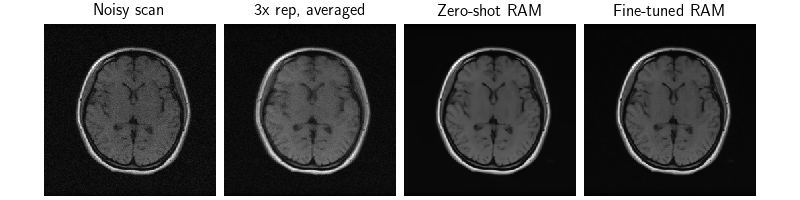
We see that the zero-shot recon is denoised, but details are blurry. The fine-tuned recon has clearer details, which is both less noisy than than the input data, but less blurry than the averaged image.
with torch.no_grad():
x_ft = model(y.to(device), physics)
dinv.utils.plot(
{
"Noisy scan": y,
"3x rep, averaged": x,
"Zero-shot RAM": x_net,
"Fine-tuned RAM": x_ft,
},
)
- References:
Total running time of the script: (0 minutes 27.793 seconds)