
Note
New to DeepInverse? Get started with the basics with the 5 minute quickstart tutorial..
Fitting NIQE on a custom dataset#
This example shows how to fit deepinv.loss.metric.NIQE on a new dataset, and use it
to evaluate denoiser performance.
NIQE is a no-reference image quality metric that compares local image statistics against those of pristine (distortion-free) images. Fitting NIQE on a domain-specific dataset can better capture the expected image characteristics.
In this example, we fit NIQE on DIV2K. DIV2K is also natural imaging data, but the image quality and sharpness is higher than the dataset NIQE was originally fitted on, so the resulting weights characterise a sharper, higher-quality prior while remaining valid NIQE statistics.
To apply this procedure to your own data, any dataset returning RGB or single-channel
tensors will work. The denominator constructor argument divides input pixels before
computing statistics; it serves two purposes: keeping pixel magnitudes from dominating
the local-statistics computation, and matching the input scale to the scale the weights
were fitted on. Two consequences:
When using the bundled original NIQE weights (which were fitted on [0, 255] data with
denominator=1), inputs must reach NIQE on a comparable [0, 255] scale. So for [0, 1] data, passdenominator=1/255(x / (1/255) = 255 * x), or scale to [0, 255] before calling and leavedenominator=1.When fitting your own weights, the only requirement is that the same
denominatoris used at fit and evaluation time. The absolute scale is up to you.
In this example we want to compare the original and DIV2K-fitted weights on the same
inputs, so we keep both on the [0, 255] scale: the fitting transform multiplies by 255
(default denominator=1 at fit time), and at evaluation we scale the denoised [0, 1]
outputs to [0, 255] before passing them to either NIQE instance.
We perform 5-fold cross-validation on the DIV2K validation set (80 fit / 20 test per fold) and compare original NIQE weights against DIV2K-fitted weights at noise level σ=0.05. A key finding is that the DIV2K-fitted NIQE assigns systematically higher (worse) scores to over-smoothed outputs (e.g. large median filters), reflecting that it is more sensitive to the loss of fine texture detail captured in the DIV2K prior.
Setup#
Selected GPU 0 with 1453.25 MiB free memory
Define transforms and load DIV2K#
We create two instances of DIV2K with different transforms: one that scales pixel values to [0, 255] for fitting NIQE weights, and one that keeps values in [0, 1] for denoising.
crop_size = 1024
fit_transform = Compose(
[
ToTensor(),
CenterCrop(crop_size),
Lambda(lambda x: x * 255),
]
)
test_transform = Compose(
[
ToTensor(),
CenterCrop(crop_size),
]
)
div2k_fit = dinv.datasets.DIV2K(
root=dinv.utils.get_data_home(), mode="val", download=True, transform=fit_transform
)
div2k_fit.x_paths = natsorted(div2k_fit.x_paths)
div2k_test = dinv.datasets.DIV2K(
root=dinv.utils.get_data_home(),
mode="val",
download=False,
transform=test_transform,
)
div2k_test.x_paths = natsorted(div2k_test.x_paths)
n_images = len(div2k_fit)
all_indices = list(range(n_images))
/local/jtachell/deepinv/deepinv/examples/metrics/demo_custom_niqe.py:82: DeprecationWarning: Function 'get_data_home' is deprecated and will be removed in a future version.
root=dinv.utils.get_data_home(), mode="val", download=True, transform=fit_transform
0%| | 0/448993893 [00:00<?, ?it/s]
1%|▏ | 5.56M/428M [00:00<00:07, 58.0MB/s]
4%|▍ | 16.2M/428M [00:00<00:04, 89.2MB/s]
6%|▌ | 26.6M/428M [00:00<00:04, 98.4MB/s]
9%|▊ | 37.3M/428M [00:00<00:03, 104MB/s]
11%|█ | 48.0M/428M [00:00<00:03, 106MB/s]
14%|█▎ | 58.6M/428M [00:00<00:03, 108MB/s]
16%|█▌ | 69.3M/428M [00:00<00:03, 109MB/s]
19%|█▊ | 79.9M/428M [00:00<00:03, 110MB/s]
21%|██ | 90.5M/428M [00:00<00:03, 110MB/s]
24%|██▎ | 101M/428M [00:01<00:03, 108MB/s]
26%|██▌ | 111M/428M [00:01<00:03, 107MB/s]
28%|██▊ | 122M/428M [00:01<00:03, 106MB/s]
31%|███ | 132M/428M [00:01<00:02, 105MB/s]
33%|███▎ | 142M/428M [00:01<00:02, 106MB/s]
36%|███▌ | 153M/428M [00:01<00:02, 108MB/s]
38%|███▊ | 164M/428M [00:01<00:02, 109MB/s]
41%|████ | 174M/428M [00:01<00:02, 110MB/s]
43%|████▎ | 185M/428M [00:01<00:02, 108MB/s]
46%|████▌ | 195M/428M [00:01<00:02, 108MB/s]
48%|████▊ | 205M/428M [00:02<00:02, 107MB/s]
50%|█████ | 216M/428M [00:02<00:02, 107MB/s]
53%|█████▎ | 226M/428M [00:02<00:01, 106MB/s]
55%|█████▌ | 236M/428M [00:02<00:01, 107MB/s]
58%|█████▊ | 247M/428M [00:02<00:01, 108MB/s]
60%|██████ | 258M/428M [00:02<00:01, 109MB/s]
63%|██████▎ | 268M/428M [00:02<00:01, 106MB/s]
65%|██████▍ | 278M/428M [00:02<00:01, 106MB/s]
67%|██████▋ | 288M/428M [00:02<00:01, 105MB/s]
70%|██████▉ | 298M/428M [00:02<00:01, 105MB/s]
72%|███████▏ | 309M/428M [00:03<00:01, 106MB/s]
74%|███████▍ | 319M/428M [00:03<00:01, 105MB/s]
77%|███████▋ | 329M/428M [00:03<00:00, 104MB/s]
79%|███████▉ | 340M/428M [00:03<00:00, 106MB/s]
82%|████████▏ | 350M/428M [00:03<00:00, 108MB/s]
84%|████████▍ | 361M/428M [00:03<00:00, 109MB/s]
87%|████████▋ | 372M/428M [00:03<00:00, 109MB/s]
89%|████████▉ | 382M/428M [00:03<00:00, 110MB/s]
92%|█████████▏| 393M/428M [00:03<00:00, 111MB/s]
94%|█████████▍| 404M/428M [00:03<00:00, 112MB/s]
97%|█████████▋| 415M/428M [00:04<00:00, 112MB/s]
99%|█████████▉| 426M/428M [00:04<00:00, 112MB/s]
100%|██████████| 428M/428M [00:04<00:00, 107MB/s]
Extracting: 0%| | 0/101 [00:00<?, ?it/s]
Extracting: 3%|▎ | 3/101 [00:00<00:04, 22.98it/s]
Extracting: 6%|▌ | 6/101 [00:00<00:04, 23.00it/s]
Extracting: 9%|▉ | 9/101 [00:00<00:03, 24.86it/s]
Extracting: 12%|█▏ | 12/101 [00:00<00:03, 25.49it/s]
Extracting: 15%|█▍ | 15/101 [00:00<00:04, 20.75it/s]
Extracting: 18%|█▊ | 18/101 [00:00<00:03, 22.18it/s]
Extracting: 21%|██ | 21/101 [00:00<00:04, 19.86it/s]
Extracting: 24%|██▍ | 24/101 [00:01<00:03, 19.57it/s]
Extracting: 27%|██▋ | 27/101 [00:01<00:03, 20.97it/s]
Extracting: 30%|██▉ | 30/101 [00:01<00:04, 17.73it/s]
Extracting: 32%|███▏ | 32/101 [00:01<00:04, 16.10it/s]
Extracting: 34%|███▎ | 34/101 [00:01<00:04, 14.34it/s]
Extracting: 36%|███▌ | 36/101 [00:01<00:04, 14.69it/s]
Extracting: 40%|███▉ | 40/101 [00:02<00:03, 19.56it/s]
Extracting: 43%|████▎ | 43/101 [00:02<00:03, 18.23it/s]
Extracting: 45%|████▍ | 45/101 [00:02<00:03, 16.50it/s]
Extracting: 48%|████▊ | 48/101 [00:02<00:02, 17.86it/s]
Extracting: 50%|████▉ | 50/101 [00:02<00:02, 18.07it/s]
Extracting: 53%|█████▎ | 54/101 [00:02<00:02, 22.28it/s]
Extracting: 56%|█████▋ | 57/101 [00:02<00:02, 20.15it/s]
Extracting: 59%|█████▉ | 60/101 [00:03<00:02, 19.00it/s]
Extracting: 62%|██████▏ | 63/101 [00:03<00:02, 18.27it/s]
Extracting: 65%|██████▌ | 66/101 [00:03<00:01, 19.21it/s]
Extracting: 67%|██████▋ | 68/101 [00:03<00:01, 17.44it/s]
Extracting: 69%|██████▉ | 70/101 [00:03<00:01, 17.56it/s]
Extracting: 72%|███████▏ | 73/101 [00:03<00:01, 20.11it/s]
Extracting: 75%|███████▌ | 76/101 [00:03<00:01, 21.44it/s]
Extracting: 78%|███████▊ | 79/101 [00:04<00:01, 20.59it/s]
Extracting: 81%|████████ | 82/101 [00:04<00:00, 21.95it/s]
Extracting: 84%|████████▍ | 85/101 [00:04<00:00, 19.28it/s]
Extracting: 87%|████████▋ | 88/101 [00:04<00:00, 19.29it/s]
Extracting: 90%|█████████ | 91/101 [00:04<00:00, 16.85it/s]
Extracting: 94%|█████████▍| 95/101 [00:04<00:00, 19.49it/s]
Extracting: 97%|█████████▋| 98/101 [00:05<00:00, 16.47it/s]
Extracting: 100%|██████████| 101/101 [00:05<00:00, 17.68it/s]
Extracting: 100%|██████████| 101/101 [00:05<00:00, 18.87it/s]
Dataset has been successfully downloaded.
/local/jtachell/deepinv/deepinv/examples/metrics/demo_custom_niqe.py:86: DeprecationWarning: Function 'get_data_home' is deprecated and will be removed in a future version.
root=dinv.utils.get_data_home(),
Define denoisers#
We compare DRUNet against MedianFilter at two kernel sizes. At inference time we wrap
each call in torch.autocast(..., dtype=torch.float16) so DRUNet fits in GPU memory
at the 1024×1024 crop size used here.
denoisers = {
"DRUNet": dinv.models.DRUNet(pretrained="download", device=device),
"Median (k=6)": dinv.models.MedianFilter(kernel_size=6),
"Median (k=9)": dinv.models.MedianFilter(kernel_size=9),
}
Load original NIQE weights#
Constructing deepinv.loss.metric.NIQE without an explicit weights_path
loads the original published NIQE weights bundled with the package. We use this
instance as the baseline for comparison against our custom-fitted weights.
niqe_original = dinv.loss.metric.NIQE(device="cpu")
Fit NIQE and save/load weights#
To fit NIQE on a custom dataset, we construct a NIQE instance with weights_path=None
(which skips loading the bundled weights, as they would be overwritten anyway) and call
deepinv.loss.metric.NIQE.create_weights() with a dataset of pristine images.
This populates the instance’s statistics in-place. The same object can then be called
directly to score new images.
To persist the fitted weights for reuse, pass save_path="my_weights.pt" to
create_weights. In a later session, load them back via
NIQE(weights_path="my_weights.pt"). Here we do not save: weights are computed
on each fold of the cross-validation below.
def fit_niqe(fit_subset: Subset) -> dinv.loss.metric.NIQE:
print(f" Fitting NIQE on {len(fit_subset)} images...")
niqe = dinv.loss.metric.NIQE(weights_path=None, device="cpu")
niqe.create_weights(fit_subset)
return niqe
Run 5-fold cross-validation#
We split the 100 DIV2K validation images into 5 folds of 20 images each. For each fold, we fit NIQE on the remaining 80 images and evaluate on the held-out 20.
sigma = 0.05
fold_size = n_images // 5
results = {
denoiser_name: {"original_niqe": [], "div2k_niqe": []}
for denoiser_name in denoisers.keys()
}
torch.manual_seed(16 * 16)
for fold in range(5):
print(f"Fold {fold + 1} / 5")
test_indices = all_indices[fold * fold_size : (fold + 1) * fold_size]
fit_indices = (
all_indices[: fold * fold_size] + all_indices[(fold + 1) * fold_size :]
)
fit_subset = Subset(div2k_fit, fit_indices)
test_subset = Subset(div2k_test, test_indices)
niqe_fitted = fit_niqe(fit_subset)
for i, img in enumerate(test_subset):
img = img.unsqueeze(0)
noisy = img + sigma * torch.randn_like(img)
images = {}
with (
torch.no_grad(),
torch.autocast(device_type=device.type, dtype=torch.float16),
):
for name, denoiser in denoisers.items():
images[name] = denoiser(noisy.to(device), sigma).cpu()
for name, im in images.items():
im_255 = im.to(torch.float32) * 255
results[name]["original_niqe"].append(float(niqe_original(im_255)))
results[name]["div2k_niqe"].append(float(niqe_fitted(im_255)))
Fold 1 / 5
Fitting NIQE on 80 images...
Fold 2 / 5
Fitting NIQE on 80 images...
Fold 3 / 5
Fitting NIQE on 80 images...
Fold 4 / 5
Fitting NIQE on 80 images...
Fold 5 / 5
Fitting NIQE on 80 images...
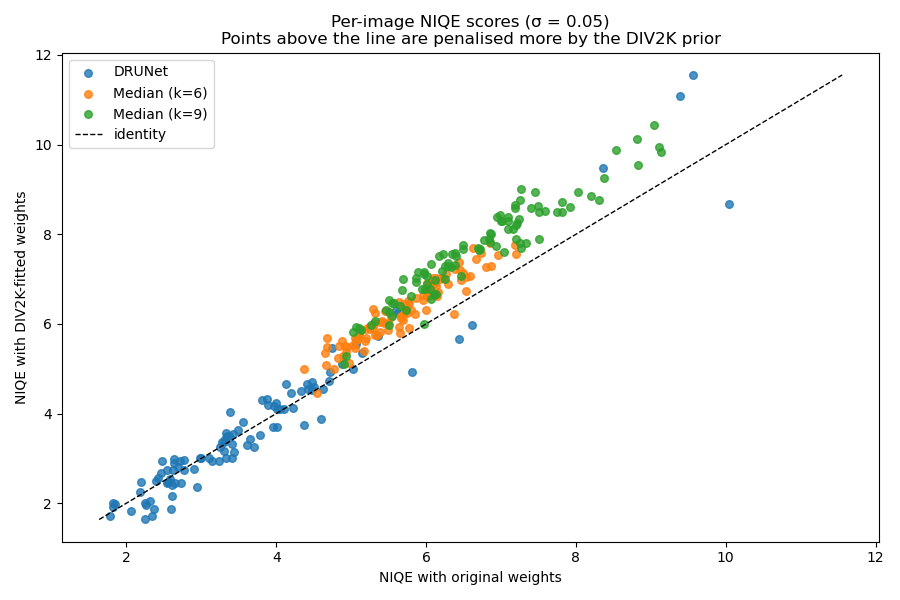
Scatter plot: original vs DIV2K-fitted NIQE#
Each point represents one test image, coloured by method. The x-axis shows the score under original weights and the y-axis shows the score under DIV2K-fitted weights. Points above the identity line are penalised more by the DIV2K prior.
The median filters’ NIQE score have a systematic upward shift: the DIV2K prior, fitted on higher-quality natural images, is more sensitive to over-smoothing and penalises the blurring introduced by large median filters more strongly than the original weights fitted on lower-quality natural images.
DRUNet introduces less smoothing and has a less systematic shift.
fig, ax = plt.subplots(figsize=(9, 6))
all_orig, all_div2k = [], []
print(
"Average relative change by utilizing DIV2K fitted NIQE instead of original NIQE:"
)
for name in denoisers.keys():
x = np.array(results[name]["original_niqe"])
y = np.array(results[name]["div2k_niqe"])
avg_relative_shift = np.mean((y - x) / x)
print(f"{name}: {float(avg_relative_shift) * 100:.3f} %")
mask = np.isfinite(x) & np.isfinite(y)
x, y = x[mask], y[mask]
all_orig.append(x)
all_div2k.append(y)
ax.scatter(x, y, s=30, label=name, alpha=0.8)
all_orig = np.concatenate(all_orig)
all_div2k = np.concatenate(all_div2k)
lim_min = min(all_orig.min(), all_div2k.min())
lim_max = max(all_orig.max(), all_div2k.max())
ax.plot([lim_min, lim_max], [lim_min, lim_max], "k--", linewidth=1, label="identity")
ax.set_xlabel("NIQE with original weights")
ax.set_ylabel("NIQE with DIV2K-fitted weights")
ax.set_title(
f"Per-image NIQE scores (σ = {sigma})\nPoints above the line are penalised more by the DIV2K prior"
)
ax.legend()
plt.tight_layout()
plt.show()
Average relative change by utilizing DIV2K fitted NIQE instead of original NIQE:
DRUNet: -0.273 %
Median (k=6): 10.488 %
Median (k=9): 14.334 %
Visual comparison between different denoisers#
Finally, we visually confirm the blurring introduced by the median filters, which is absent in the ground-truth and DRUNet outputs.
methods_all = ["gt", "noisy"] + list(denoisers.keys())
c = crop_size // 2
sample_img = div2k_test[5][:, c - 128 : c + 128, c - 128 : c + 128].unsqueeze(0)
sample_noisy = sample_img + sigma * torch.randn_like(sample_img)
images = {"gt": sample_img, "noisy": sample_noisy}
with torch.no_grad(), torch.autocast(device_type=device.type, dtype=torch.float16):
for name, denoiser in denoisers.items():
images[name] = denoiser(sample_noisy.to(device), 0.05).cpu()
plot(
[images[m] for m in methods_all],
titles=methods_all,
vmin=0,
vmax=1,
rescale_mode="clip",
)

Total running time of the script: (4 minutes 19.631 seconds)