
PatchNR#
- class deepinv.optim.PatchNR(normalizing_flow=None, pretrained=None, patch_size=6, channels=1, num_layers=5, sub_net_size=256, device='cpu')[source]#
Bases:
PriorPatch prior via normalizing flows.
The prior is defined as the sum of the negative log-likelihoods of all (overlapping) patches of the image under a learned normalizing flow model [1]. Denoting by \(P_i x\) the \(i\)-th patch of image \(x\) (out of \(N\)) and by \(f_\theta\) the normalizing flow with parameters \(\theta\), the prior reads
\[\reg{x} = \frac{1}{N} \sum_{i=1}^{N} -\log p_\theta(P_i x)\]where \(p_\theta\) is the patch distribution implicitly defined by the flow. Applying the change-of-variables formula with the standard Gaussian base distribution \(p_z = \mathcal{N}(0, I)\), this expands to
\[\reg{x} = \frac{1}{N} \sum_{i=1}^{N} \left( \frac{1}{2}\| f_\theta(P_i x) \|_2^2 - \log \left|\det J_{f_\theta}(P_i x)\right| \right)\]where \(J_{f_\theta}\) is the Jacobian of \(f_\theta\). Both terms are computed in a single forward pass through the flow, which returns the latent code \(z = f_\theta(P_i x)\) and the log-determinant \(\log |\det J_{f_\theta}(P_i x)|\) simultaneously.
The forward method evaluates this negative log likelihood.
- Parameters:
normalizing_flow (torch.nn.Module) – describes the normalizing flow of the model. Generally it can be any
torch.nn.Modulesupporting backpropagation. It takes a (batched) tensor of flattened patches and the booleanrev(defaultFalse) as input and returns(latent, log_det_jacobian)as output. Ifrev=True, it applies the inverse of the flow. When set toNone, a GLOW-style invertible neural network is built, where the number of coupling blocks and the hidden neurons of the sub-networks are determined bynum_layersandsub_net_sizerespectively. IfNone, it is set todeepinv.optim.prior.NormalizingFlowmodel.pretrained (str) – Define pretrained weights by its path checkpoint,
Nonefor random initialization,"PatchNR_lodopab_small2"for the weights from the limited-angle CT example.patch_size (int) – size of patches
channels (int) – number of channels for the underlying images/patches.
num_layers (int) – defines the number of coupling blocks of the normalizing flow if
normalizing_flowisNone.sub_net_size (int) – defines the number of hidden neurons in the subnetworks of the normalizing flow if
normalizing_flowisNone.device (str) – used device
- Examples:
>>> import torch >>> import deepinv as dinv >>> prior = dinv.optim.PatchNR(patch_size=6, channels=1) >>> x = torch.randn(2, 10, 36) # (batch, n_patches, patch_size^2 * channels) >>> nll = prior.fn(x) >>> nll.shape torch.Size([2, 10])
- References:
- fn(x, *args, **kwargs)[source]#
Evaluates the negative log likelihood function of th PatchNR.
- Parameters:
x (torch.Tensor) – Variable \(x\) at which the prior is computed.
- Returns:
(
torch.Tensor) prior \(g(x)\).- Return type:
Examples using PatchNR:#
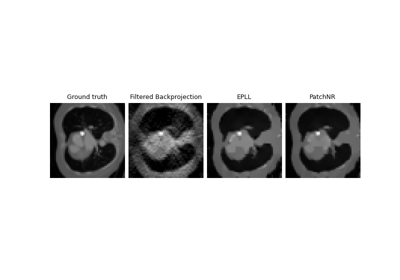
Patch priors for limited-angle computed tomography